30 Days of MLOps Challenge · Day 6
 Training ML Models with Scikit-learn & TensorFlow – Build & Save Your Models Like a Pro
Training ML Models with Scikit-learn & TensorFlow – Build & Save Your Models Like a Pro
Understand ML model training with Scikit‑learn and TensorFlow, and learn to persist models for reliable deployment.
💡 Hey — It's Aviraj Kawade 👋
💡 Premium: Automating AI/Cloud/DevOps with n8n
Key Learnings
- Train models with Scikit‑learn and TensorFlow.
- Differences: classic ML vs deep learning workflows.
- Persist models using joblib/pickle/SavedModel for deployment.
- Modular training pipelines: load → preprocess → train → evaluate → save.
In Simple Terms: What is an ML Model?
An ML model learns patterns from data to make predictions. It uses features, learned weights, and an algorithm to output predictions on new inputs.
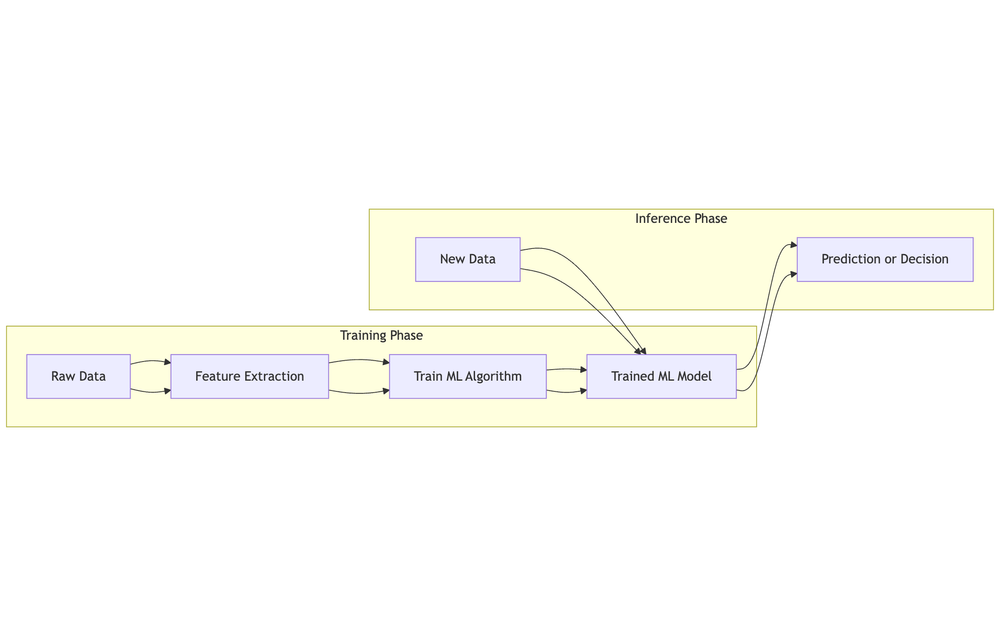
Scikit‑learn Overview
Open‑source Python library with consistent APIs for classification, regression, clustering, model selection, preprocessing, and more. Ideal for prototyping and small‑to‑medium projects.
Core Concepts
- Estimators (fit), Predictors (predict), Transformers (transform)
- Pipelines, model selection, cross‑validation, metrics
- Model persistence using joblib or pickle
Project: Student Pass/Fail Prediction (Scikit‑learn)
Build a pipeline to predict student outcomes and save the trained model.
# requirements
pip install pandas scikit-learn joblib fastapi uvicorn
# data_generation.py
import pandas as pd
import random
random.seed(42)
schools = ['Greenwood High', 'Sunrise Public', 'Hillview School']
data = []
for _ in range(100):
school = random.choice(schools)
study_hours = round(random.uniform(1, 10), 1)
absences = random.randint(0, 10)
grade = round(random.uniform(40, 100), 1)
passed = 1 if grade >= 50 else 0
data.append([school, study_hours, absences, grade, passed])
df = pd.DataFrame(data, columns=['school', 'study_hours', 'absences', 'grade', 'passed'])
df.to_csv("students.csv", index=False)
# train_model.py
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
import joblib
df = pd.read_csv("students.csv")
X = df.drop("passed", axis=1)
y = df["passed"]
preprocessor = ColumnTransformer([
("school_encoder", OneHotEncoder(), ["school"])
], remainder="passthrough")
pipeline = Pipeline([
("preprocess", preprocessor),
("classifier", RandomForestClassifier(random_state=42))
])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
pipeline.fit(X_train, y_train)
joblib.dump(pipeline, "student_model.pkl")
# predict.py
import joblib
import pandas as pd
model = joblib.load("student_model.pkl")
sample = pd.DataFrame([{
"school": "Greenwood High",
"study_hours": 6.5,
"absences": 2,
"grade": 78.0
}])
pred = model.predict(sample)
print(f"Predicted: {'Pass' if pred[0] == 1 else 'Fail'}")
# serve_model.py
from fastapi import FastAPI
from pydantic import BaseModel
import pandas as pd
import joblib
app = FastAPI()
model = joblib.load("student_model.pkl")
class StudentData(BaseModel):
school: str
study_hours: float
absences: int
grade: float
@app.post("/predict")
def predict(data: StudentData):
df = pd.DataFrame([data.dict()])
prediction = model.predict(df)[0]
return {"prediction": "Pass" if prediction == 1 else "Fail"}
# run
# uvicorn serve_model:app --reload
TensorFlow Overview
Open‑source framework for ML/DL from Google. Supports CPUs/GPUs/TPUs, Keras API, TensorBoard, and production serving.
- Tensors, Keras layers, optimizers, losses, metrics
- tf.function, SavedModel format, TensorFlow Serving
Project: Time Series Forecasting (TensorFlow)
# install
pip install tensorflow pandas numpy scikit-learn
# data/generate_dataset.py
import numpy as np
import pandas as pd
days = np.arange(365)
temperature = 10 + 0.02 * days + np.sin(0.1 * days) + np.random.normal(0, 0.5, size=(365,))
df = pd.DataFrame({'day': days, 'temperature': temperature})
df.to_csv("sample_data.csv", index=False)
# src/train_model.py
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
from sklearn.preprocessing import MinMaxScaler
df = pd.read_csv("sample_data.csv")
data = df['temperature'].values.reshape(-1, 1)
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
def create_sequences(data, window_size):
X, y = [], []
for i in range(len(data) - window_size):
X.append(data[i:i+window_size])
y.append(data[i+window_size])
return np.array(X), np.array(y)
window_size = 10
X, y = create_sequences(data_scaled, window_size)
split = int(0.8 * len(X))
X_train, y_train = X[:split], y[:split]
X_test, y_test = X[split:], y[split:]
model = Sequential([
LSTM(64, input_shape=(window_size, 1)),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
predictions = model.predict(X_test)
model.save("models/saved_model")
# src/serve_model.py
from tensorflow.keras.models import load_model
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
df = pd.read_csv("sample_data.csv")
data = df['temperature'].values.reshape(-1, 1)
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
model = load_model("models/saved_model")
window_size = 10
recent_sequence = data_scaled[-window_size:].reshape(1, window_size, 1)
future_prediction = model.predict(recent_sequence)
print(f"Predicted next day's temperature: {future_prediction[0][0]:.2f}")
Why Save Models?
- Deployment: load in APIs/apps without retraining.
- Reproducibility: consistent results over time.
- Performance: avoid expensive retraining.
- Portability/versioning across teams and systems.
What to Use
| Tool | Best For | Format | Notes |
|---|---|---|---|
| joblib | Scikit‑learn models | .pkl | Efficient for numpy arrays |
| pickle | General Python objects | .pkl | Flexible, less efficient for big numpy models |
| SavedModel | TensorFlow/Keras | dir | Graph+weights+metadata; great for TF Serving |
Modular Training Pipelines
# pipeline.py
from data_loader import load_data
from preprocessing import preprocess_data
from model import build_model
from train import train_model
from evaluate import evaluate_model
from save_load import save_model
raw_data = load_data("data/data.csv")
X_train, X_test, y_train, y_test = preprocess_data(raw_data)
model = build_model()
trained_model = train_model(model, X_train, y_train)
evaluate_model(trained_model, X_test, y_test)
save_model(trained_model, "models/model.pkl")
- Maintainable, testable, reusable components.
- Scales to multiple datasets/models.
Challenges
- Feature engineer a CSV with Pandas.
- Train and save a Scikit‑learn model on Iris or Titanic.
- Train a TensorFlow model on MNIST or Fashion‑MNIST and save.
- Evaluate and log metrics (accuracy, loss) to JSON/text.
- Modularize training into data.py, train.py, evaluate.py, save.py.
- Load saved models and run inference on new samples.
- Document the workflow in README.md.