30 Days of MLOps Challenge · Day 7
 Model Experiment Tracking with MLflow – Log It or Lose It
Model Experiment Tracking with MLflow – Log It or Lose It
Track parameters, metrics, and artifacts across runs so you can reproduce, compare, and collaborate effectively.
💡 Hey — It's Aviraj Kawade 👋
Key Learnings
- Why experiment tracking is critical (reproducibility, comparability, collaboration).
- MLflow components: Tracking, Projects, Models, Registry.
- Track params/metrics/artifacts with the Tracking API.
- Log models and register for deployment.
What is ML Experiment Tracking?
Logging, organizing, and comparing ML runs to know which changes improved results and to reproduce them reliably.
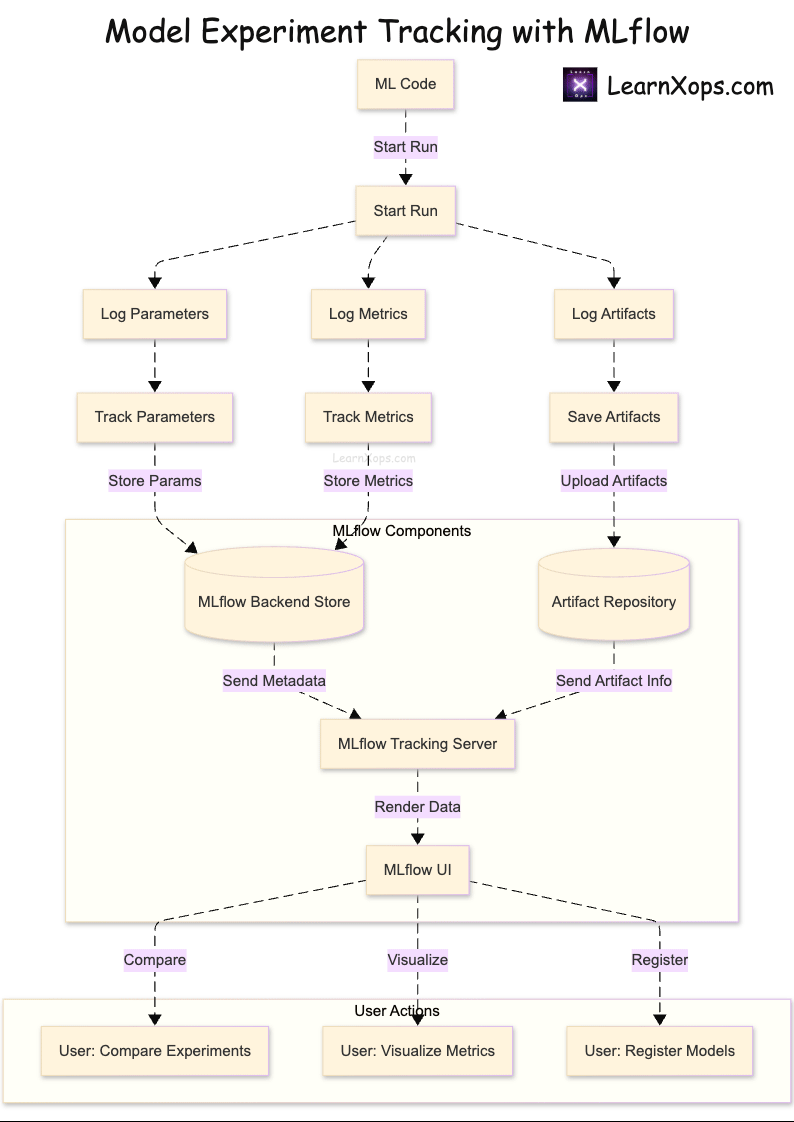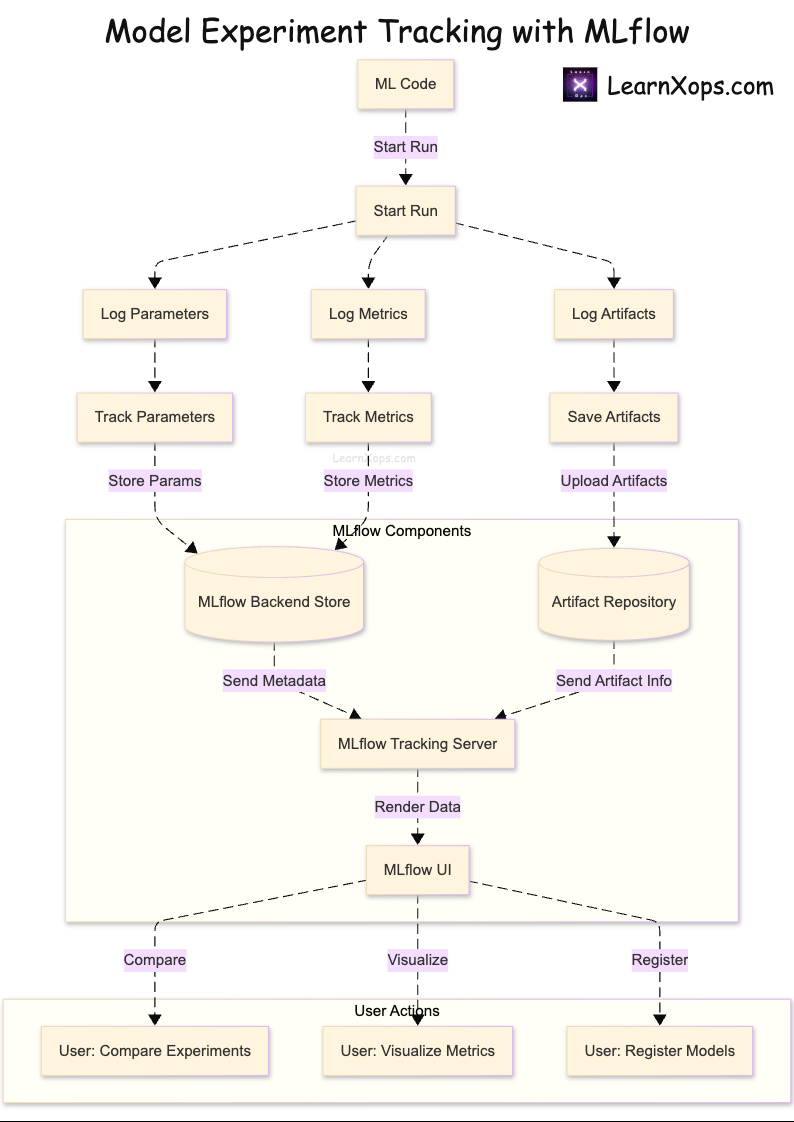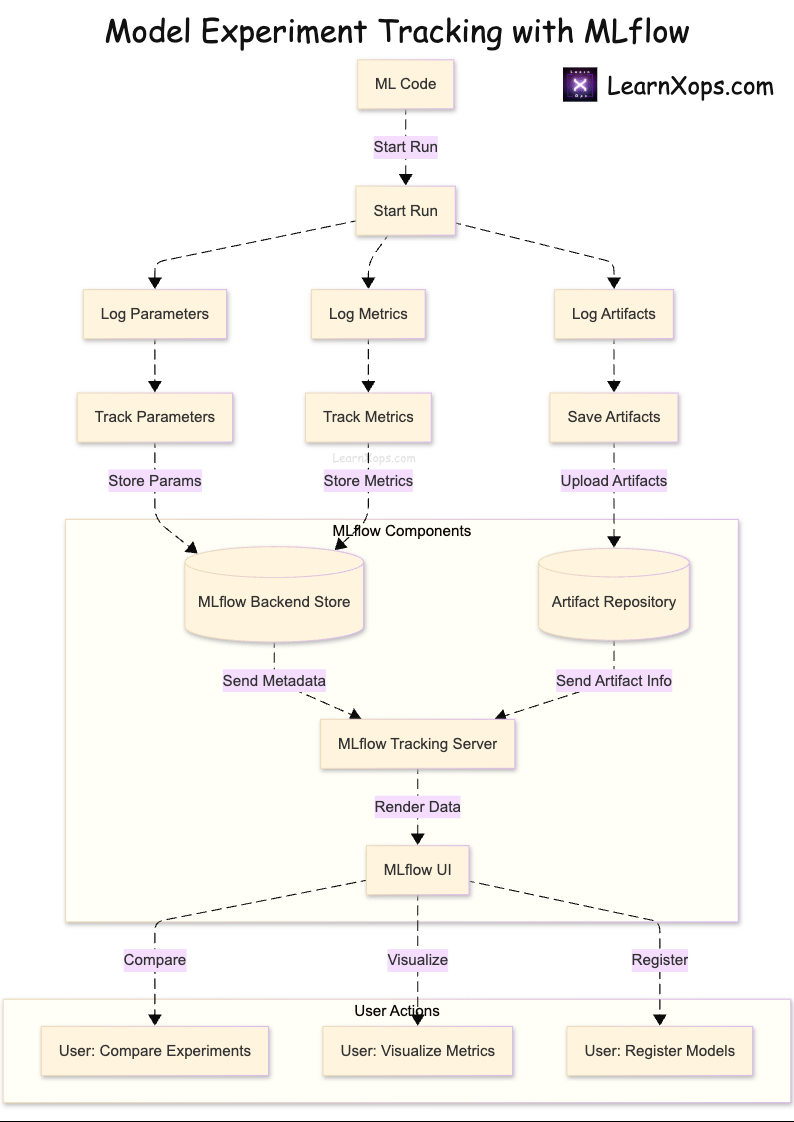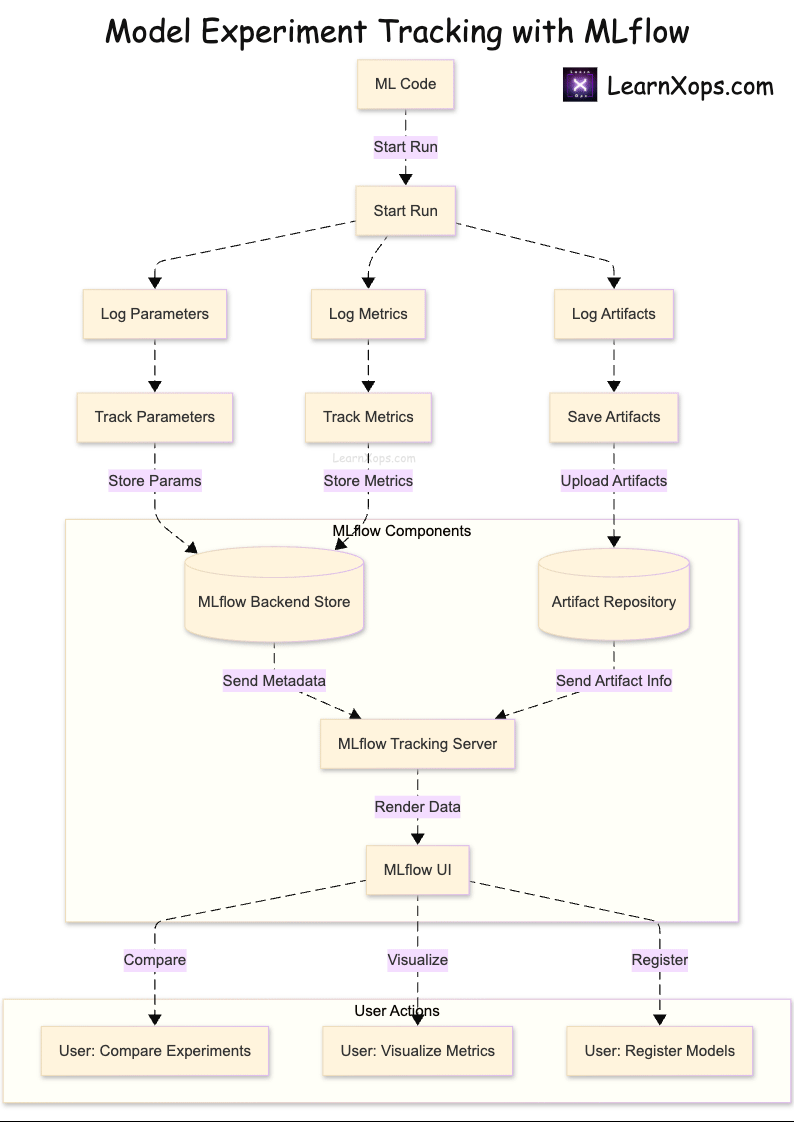
What is MLflow?
Open‑source platform for managing the ML lifecycle: Tracking, Projects, Models, and Registry. Works with any ML library.
| Component | Purpose |
|---|---|
| Tracking | Logs and queries experiments |
| Projects | Reproducible runs with environment definition |
| Models | Standard model packaging across frameworks |
| Registry | Central store with versions and stages |
Track with the MLflow API
pip install mlflow
import mlflow
mlflow.set_experiment("my-experiment")
with mlflow.start_run(run_name="my-first-run") as run:
mlflow.log_param("learning_rate", 0.01)
mlflow.log_param("optimizer", "adam")
mlflow.log_metric("accuracy", 0.95)
mlflow.log_metric("loss", 0.05)
with open("model.txt", "w") as f:
f.write("This is a dummy model file.")
mlflow.log_artifact("model.txt")
print("Run ID:", run.info.run_id)
for step in range(5):
mlflow.log_metric("accuracy", 0.9 + step*0.01, step=step)
Accessing Run Data
from mlflow.tracking import MlflowClient
client = MlflowClient()
runs = client.search_runs(experiment_ids=["0"]) # default experiment id
for run in runs:
print("Run ID:", run.info.run_id)
print("Params:", run.data.params)
print("Metrics:", run.data.metrics)
UI Access
# Local UI
mlflow ui
# Or as a server
mlflow server --host 127.0.0.1 --port 8080 \
--backend-store-uri sqlite:///mlruns.db \
--default-artifact-root ./artifacts
Log, Register, and Deploy
import mlflow, mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
model = RandomForestClassifier().fit(X_train, y_train)
with mlflow.start_run() as run:
mlflow.sklearn.log_model(model, artifact_path="rf_model", registered_model_name="IrisRFModel")
from mlflow.tracking import MlflowClient
client = MlflowClient()
client.create_registered_model("IrisRFModel")
client.create_model_version(
name="IrisRFModel",
source=f"{run.info.artifact_uri}/rf_model",
run_id=run.info.run_id
)
# Load from Registry
model_uri = "models:/IrisRFModel/Production"
loaded_model = mlflow.sklearn.load_model(model_uri)
# Serve
# mlflow models serve -m models:/IrisRFModel/Production -p 5001
Challenges
- Add MLflow tracking to a Sklearn or TensorFlow script.
- Log at least 3 params and 2 metrics.
- Save your trained model as an artifact.
- Run the UI and compare at least 2 runs.
- Use a file backend and custom artifact root.
- Try mlflow.projects with conda.yaml or Dockerfile.