 Scaling ML Model Inference with Kubernetes
Scaling ML Model Inference with Kubernetes
Learn scaling model inference with Kubernetes to ensure high availability and low-latency predictions in production ML systems. Mastering this enables dynamic autoscaling, cost optimization, and seamless deployment of AI workloads at scale.
We should learn scaling model inference with Kubernetes to ensure high availability and low-latency predictions in production ML systems. Mastering this enables dynamic autoscaling, cost optimization, and seamless deployment of AI workloads at scale.
📚 Key Learnings
- Why Kubernetes is ideal for scaling model inference workloads
- Understand deployment options: FastAPI/Flask containers as inference services
- How to expose model APIs using Services, Ingress, and LoadBalancers
- Scaling inference using Horizontal Pod Autoscaling (HPA) based on CPU/GPU/requests
- Explore real-world deployments on KinD/minikube, AWS EKS, and Google GKE
🧠 Learn here
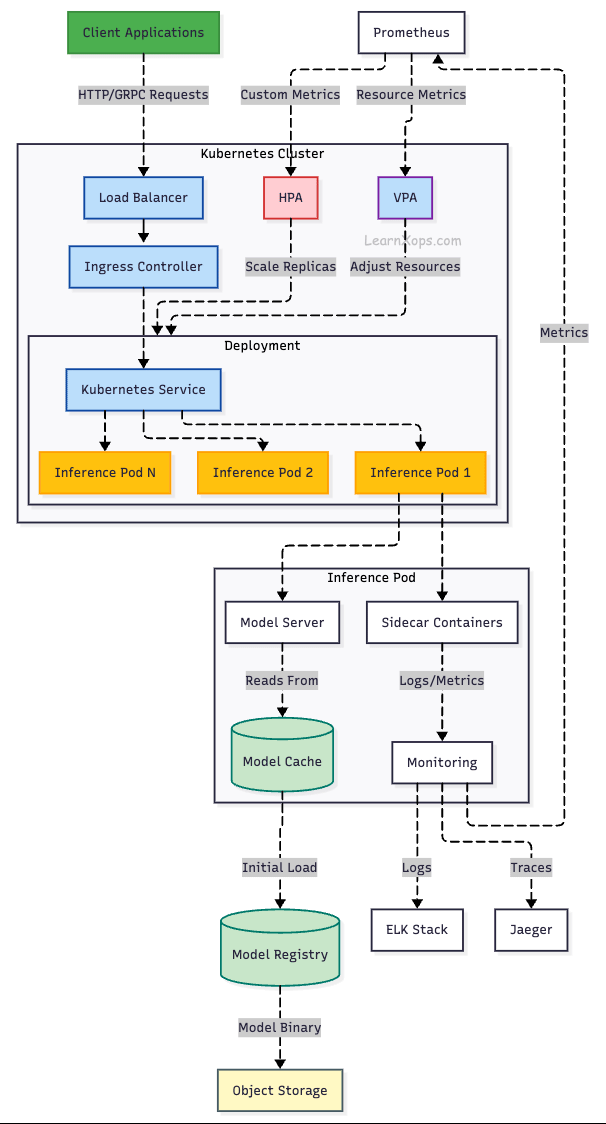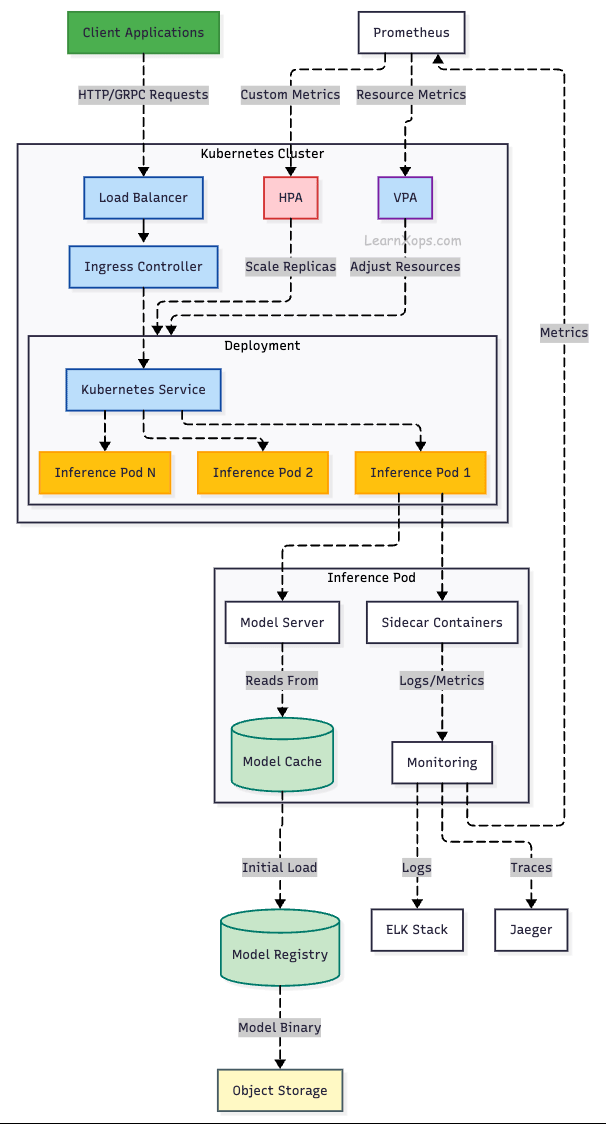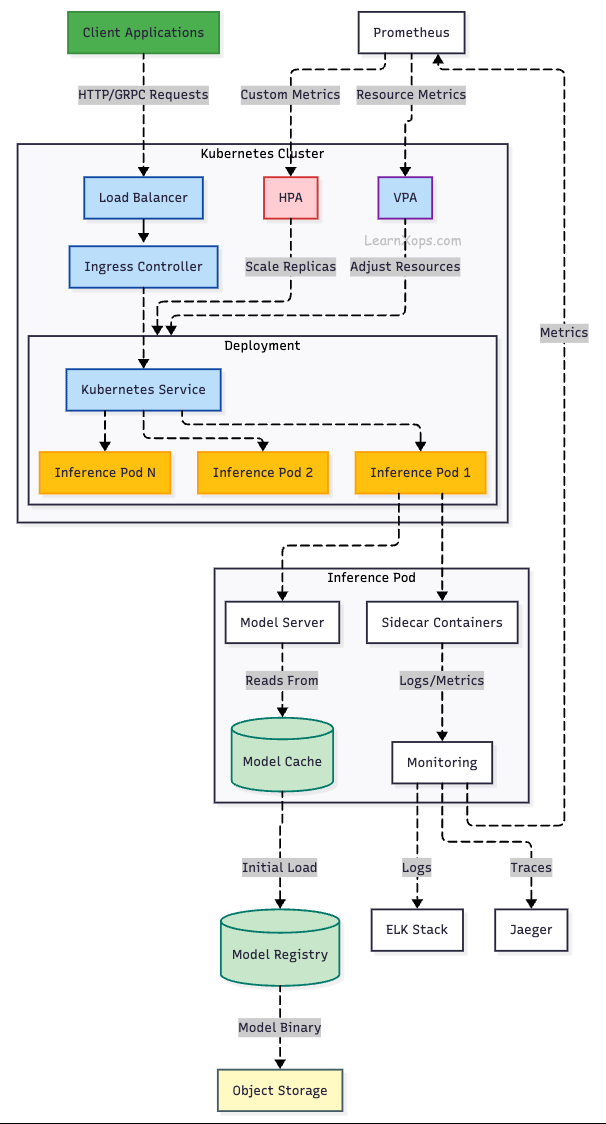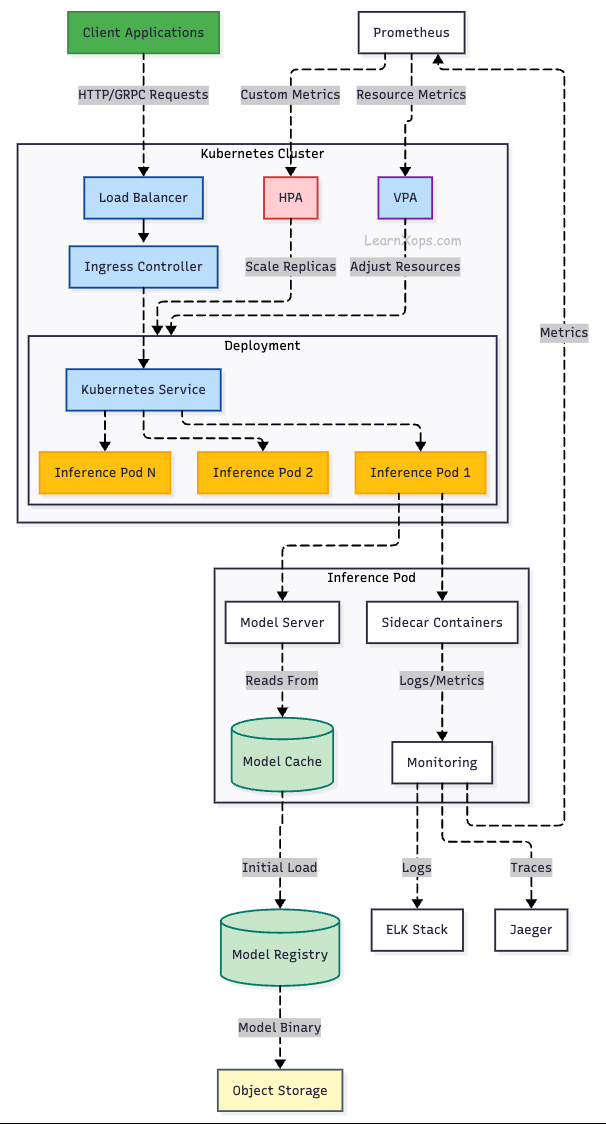
Kubernetes (K8s) has emerged as the de facto standard for deploying, scaling, and managing containerized applications. When it comes to machine learning (ML) model inference, Kubernetes offers a highly efficient and robust platform to handle dynamic and resource-intensive workloads.
Why Kubernetes is Ideal for Scaling Model Inference:
1. Horizontal Pod Autoscaling (HPA)
- Automatically scales the number of inference pods based on CPU, memory usage, or custom metrics (like request rate or latency)
- Enables responsive scaling during peak traffic periods
2. Custom Resource Definitions (CRDs) for ML
- Frameworks like Kubeflow, KServe, or Seldon Core extend Kubernetes with ML-specific capabilities
- Abstracts complex deployment logic into simple YAMLs or CRDs for versioned and repeatable deployments
3. Multi-Tenant and Resource Isolation
- Namespaces and resource quotas isolate workloads across teams, models, or services
- Prevents one model from starving resources used by another
4. GPU/TPU Scheduling and Node Affinity
- Kubernetes supports GPU/TPU acceleration with node affinity, tolerations, and taints
- Enables dynamic scheduling of inference jobs based on hardware requirements
5. Observability and Monitoring
- Native integration with Prometheus, Grafana, and OpenTelemetry for metrics, traces, and logs
- Allows you to monitor inference latency, throughput, and model performance in real time
6. Load Balancing and Canary Deployments
- Kubernetes Services + Ingress + Service Meshes (like Istio) provide advanced routing, traffic splitting, and A/B testing
- Safely roll out new versions of models without downtime
7. Autoscaling Infrastructure (Cluster Autoscaler / Karpenter)
- Scales the underlying nodes when pod demand exceeds capacity
- Efficient use of resources with cost-aware node provisioning (Karpenter)
Sample Use Case: Real-Time Fraud Detection
- Deploy a fraud detection model as a REST API using KServe on Kubernetes
- Use HPA to scale inference pods based on HTTP request rate
- Enable GPU acceleration for high-throughput scoring
- Monitor model accuracy and latency via Prometheus + Grafana
🧠 Production Considerations
- Use pod disruption budgets and readiness probes to ensure high availability
- Co-locate model and feature store pods using affinity rules for performance
- Apply network policies for secure access
AI/ML Companies Using Kubernetes
| Company | Use Case on Kubernetes |
|---|---|
| OpenAI | Scalable model serving and orchestration of inference jobs |
| Spotify | Model training and real-time personalization |
| Running inference services and recommendation engines | |
| Netflix | Content personalization and observability for ML pipelines |
| Feature store management, training workflows, inference | |
| DoorDash | Real-time ETA prediction and ML observability stack |
| NVIDIA | GPU-accelerated inference and model serving infrastructure |
| Salesforce | Einstein model deployment, monitoring, and scaling |
| Snap Inc. | Image recognition models deployed via Kubernetes |
| Shopify | Fraud detection and personalization pipelines |
Deployment Options: FastAPI & Flask Containers as Inference Services
Deploying ML models via FastAPI or Flask containers is one of the most practical approaches for serving inference workloads in both development and production environments. This method wraps your trained model in a lightweight web service, allowing for flexible and scalable deployment.
FastAPI vs Flask for Inference
| Feature | FastAPI | Flask |
|---|---|---|
| Speed | Very fast (ASGI-based) | Slower (WSGI-based) |
| Async Support | Native async/await | Requires extensions or workarounds |
| Type Hints | Full support for Pydantic & validation | Minimal support |
| Documentation | Auto-generates Swagger & ReDoc | Requires manual setup |
| Maturity | Newer, modern | Older, battle-tested |
Common Use Case
- Scenario: You have a trained ML model (e.g., sklearn, PyTorch, or TensorFlow) and want to expose it as an API for inference
- Solution: Wrap the model in a FastAPI or Flask app and containerize it using Docker
FastAPI Inference Example
# app.py
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
model = joblib.load("model.pkl")
app = FastAPI()
class InputData(BaseModel):
feature1: float
feature2: float
@app.post("/predict")
def predict(data: InputData):
pred = model.predict([[data.feature1, data.feature2]])
return {"prediction": pred.tolist()}Dockerfile
FROM python:3.9
WORKDIR /app
COPY . .
RUN pip install fastapi uvicorn scikit-learn joblib
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "80"]Flask Inference Example
# app.py
from flask import Flask, request, jsonify
import joblib
model = joblib.load("model.pkl")
app = Flask(__name__)
@app.route("/predict", methods=["POST"])
def predict():
data = request.json
pred = model.predict([[data['feature1'], data['feature2']]])
return jsonify({"prediction": pred.tolist()})Dockerfile
FROM python:3.9
WORKDIR /app
COPY . .
RUN pip install flask scikit-learn joblib
CMD ["python", "app.py"]Deployment on Kubernetes
- Build and push the container image to a registry
- Create a Kubernetes Deployment and Service manifest
- Optionally expose via Ingress for external access
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: inference-api
spec:
replicas: 2
selector:
matchLabels:
app: inference-api
template:
metadata:
labels:
app: inference-api
spec:
containers:
- name: inference-container
image: your-dockerhub-username/inference-api:latest
ports:
- containerPort: 80
resources:
limits:
cpu: "500m"
memory: "512Mi"
requests:
cpu: "250m"
memory: "256Mi"service.yaml
apiVersion: v1
kind: Service
metadata:
name: inference-service
spec:
selector:
app: inference-api
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIPExposing Model APIs on Kubernetes
Once your ML model is containerized and deployed on Kubernetes, the next critical step is exposing it for external or internal consumption. Kubernetes provides multiple mechanisms to expose services, depending on use case, security, and traffic requirements.
Key Methods to Expose Model APIs
1. ClusterIP (Default)
- Use Case: Internal-only services (e.g., model used by internal pipeline)
- Access: Not reachable from outside the cluster
apiVersion: v1
kind: Service
metadata:
name: model-service
spec:
selector:
app: model-api
ports:
- port: 80
targetPort: 80
type: ClusterIP2. NodePort
- Use Case: Expose to external users (dev/test), not recommended for production
- Access: Available on <NodeIP>:<NodePort>
apiVersion: v1
kind: Service
metadata:
name: model-service
spec:
selector:
app: model-api
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 300073. LoadBalancer (Production-grade External Access)
- Use Case: Exposing model to internet via cloud-managed external Load Balancer (e.g., AWS ELB, GCP LB)
- Access: Public IP assigned by cloud provider
apiVersion: v1
kind: Service
metadata:
name: model-service
spec:
selector:
app: model-api
type: LoadBalancer
ports:
- port: 80
targetPort: 80Cloud provider assigns an external IP:
kubectl get svc model-service4. Ingress (With NGINX/ALB/GKE Controller)
- Use Case: Route traffic via domain/subdomain (e.g., /predict) with SSL termination
- Access: Expose multiple APIs with a single LB + domain
Ingress Manifest:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: model-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: model.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: model-service
port:
number: 80Note: You need an Ingress Controller (NGINX, ALB, etc.) installed.
💡 Pro Tips
- Use ClusterIP for internal inference pipelines
- Use LoadBalancer for quick external access (dev/test/staging)
- Use Ingress for production-ready setup with domain, TLS, path-based routing
- Secure APIs with network policies, authentication, and rate limiting
Scaling Inference Using Horizontal Pod Autoscaling (HPA)
Horizontal Pod Autoscaler (HPA) is a Kubernetes feature that automatically adjusts the number of pods in a deployment based on observed metrics such as CPU usage, GPU usage, or custom request rate metrics. This makes it an ideal solution for scaling inference workloads dynamically based on traffic.
Why Use HPA for Inference APIs?
- Automatically adds/removes pods based on real-time usage
- Ensures optimal resource usage and cost efficiency
- Prevents model latency spikes during traffic surges
- Helps maintain SLA and system responsiveness
Prerequisites
- Metrics Server must be installed in your cluster
- Your deployment must define resource requests and limits for CPU/Memory
Example 1: Scale Based on CPU Usage
FastAPI/Flask deployment snippet:
resources:
requests:
cpu: "200m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"HPA Manifest:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: inference-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: inference-api
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60Example 2: Scale Based on Request Rate (Custom Metrics)
Use Prometheus Adapter to expose custom metrics like requests per second (RPS).
metrics:
- type: Pods
pods:
metric:
name: rps
target:
type: AverageValue
averageValue: "50"Example 3: GPU-Based Autoscaling (Experimental)
You can use extended HPA controllers or KEDA + NVIDIA DCGM exporter.
metrics:
- type: External
external:
metric:
name: nvidia.com/gpu_utilization
target:
type: Value
value: "60"View Scaling in Action
kubectl get hpa inference-hpa --watch💡 Best Practices
- Set proper resource requests/limits for reliable autoscaling
- Always test with load simulators (e.g., Locust, k6)
- Combine HPA with Cluster Autoscaler/Karpenter for full elasticity
- Use VPA (Vertical Pod Autoscaler) in "recommendation mode" for tuning
Real-World Inference API Deployments on KinD, Minikube, AWS EKS, and GCP GKE
Now, let's explore real-world deployment strategies for ML inference APIs (FastAPI/Flask) across different Kubernetes environments — from local development setups like KinD and Minikube to cloud-native managed clusters like AWS EKS and Google GKE.
1. Local: KinD (Kubernetes-in-Docker)
Use Case
- Fast local dev/testing for multi-node clusters
- CI pipeline simulation (GitHub Actions, etc.)
Setup
Create a cluster with a custom config (multi-node example):
# kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
kind create cluster --name ml-inference --config kind-config.yamlDeploy FastAPI Inference App
Build Docker image:
docker build -t inference-api:latest .Load image to KinD:
kind load docker-image inference-api:latest --name ml-inferenceApply manifests:
kubectl apply -f deployment.yaml
kubectl apply -f service.yamlAccess Locally
kubectl port-forward svc/inference-service 8080:80
curl http://localhost:8080/predict2. Local: Minikube
Use Case
- Ideal for quick experiments with full K8s functionality
- Supports LoadBalancer simulation
Setup
minikube start --driver=docker
minikube addons enable ingress metrics-serverDeploy Inference API:
Build and push image:
docker build -t inference-api:latest .
eval $(minikube docker-env)
docker tag inference-api:latest inference-api:localApply deployment:
kubectl apply -f deployment.yaml
kubectl apply -f service.yamlAccess Service
minikube service inference-service3. Cloud: AWS EKS
Use Case
- Production-grade managed Kubernetes for high-scale inference
Cluster Setup with eksctl
eksctl create cluster \
--name ml-inference \
--region us-east-1 \
--nodes 3 \
--node-type t3.medium \
--with-oidc \
--managedDeploy to EKS
Tag and push Docker image:
docker tag inference-api:latest .dkr.ecr.us-east-1.amazonaws.com/inference-api:latest
aws ecr get-login-password | docker login --username AWS --password-stdin
docker push /inference-api:latest Apply Kubernetes manifests:
kubectl apply -f deployment.yaml
kubectl apply -f service.yamlAccess via Load Balancer
kubectl get svc inference-serviceUse the EXTERNAL-IP to test:
curl http:///predict 4. Cloud: Google Kubernetes Engine (GKE)
Use Case
- Auto-upgrades, deep GCP service integration
Setup with gcloud
gcloud container clusters create ml-inference \
--zone us-central1-a \
--num-nodes 3 \
--enable-ip-aliasBuild & Push Image to Google Container Registry (GCR)
docker tag inference-api gcr.io//inference-api
docker push gcr.io//inference-api Deploy App
kubectl apply -f deployment.yaml
kubectl apply -f service.yamlExternal Access
kubectl get svc inference-service
curl http:///predict 🧠 Best Practices Across All Platforms
- Use Helm/Kustomize for environment-specific configuration
- Use ConfigMaps and Secrets for API config and auth keys
- Enable PodDisruptionBudgets and readiness/liveness probes
- Use HorizontalPodAutoscaler for scalable deployments
🔥 Challenges
Basic Deployment
- Deploy your ML inference API on Minikube or EKS with proper YAML
- Expose the service using type: LoadBalancer or Ingress
- Access the model from browser or Postman and test predictions
Autoscaling
- Set CPU requests/limits for your container
- Enable HPA and simulate high load using ab or hey tools
- Observe pod scaling (kubectl get hpa and kubectl get pods)
Advanced
- Deploy on EKS using eksctl or Terraform
- Set up logging and monitoring for your inference workload (Prometheus/Grafana)
- Use taints and tolerations or node selectors to isolate inference workloads (prod-like setup)
- Use KEDA for event-driven autoscaling based on request queue size (e.g., Kafka, SQS)