 Model Registry – Managing and Versioning ML Models
Model Registry – Managing and Versioning ML Models
Learn Model Registry to systematically manage, version, and track ML models across their lifecycle, ensuring reproducibility and smooth transitions between development, staging, and production. It enables better collaboration, auditability, and automated model promotion in real-world ML workflows.
We should learn Model Registry to systematically manage, version, and track ML models across their lifecycle, ensuring reproducibility and smooth transitions between development, staging, and production. It enables better collaboration, auditability, and automated model promotion in real-world ML workflows.
📚 Key Learnings
- Understand the role of a Model Registry in production ML systems
- Learn how to track, store, and version models throughout the ML lifecycle
- Discover how to promote models between stages (e.g., Staging → Production)
- Use tools like MLflow Model Registry, SageMaker Model Registry, or DVC + Git
🧠 Learn here
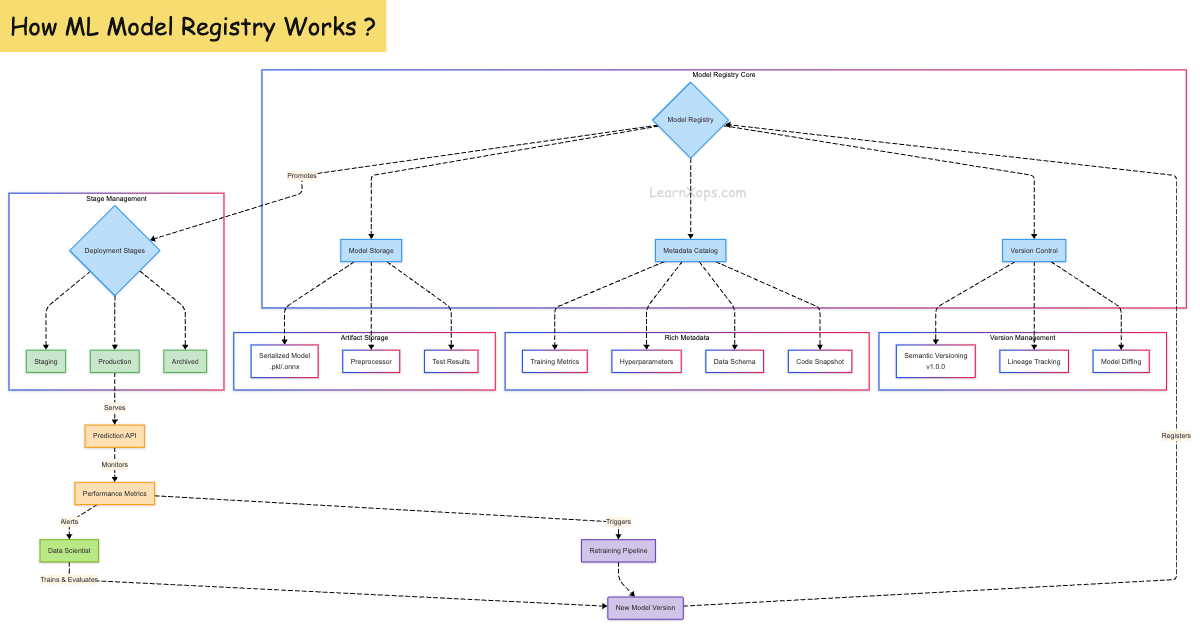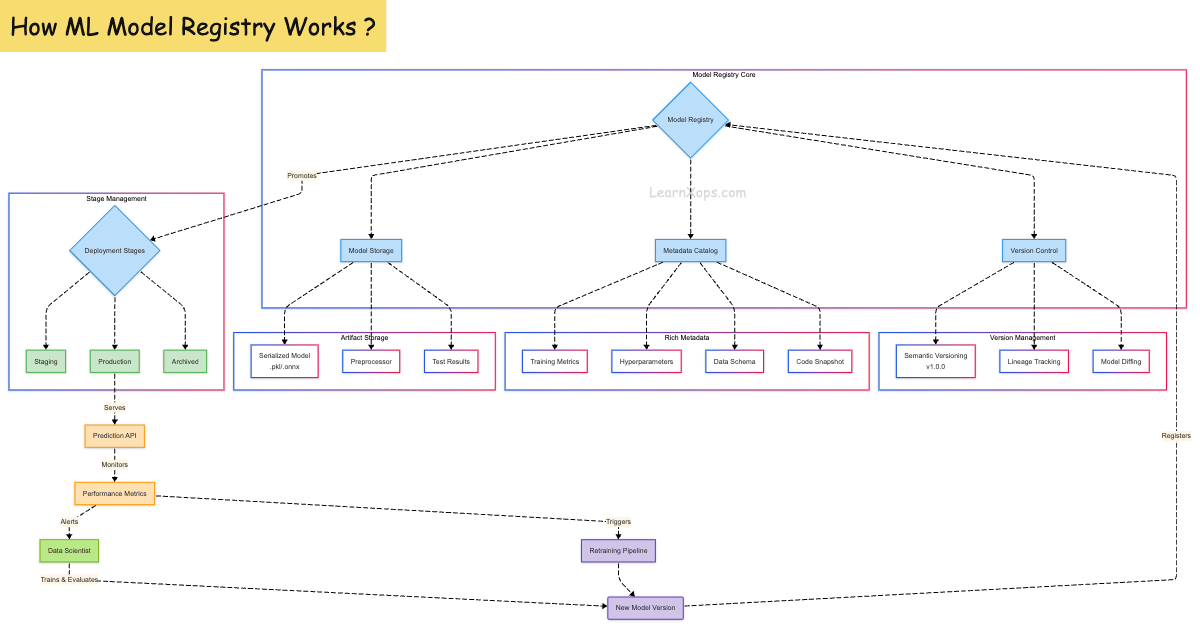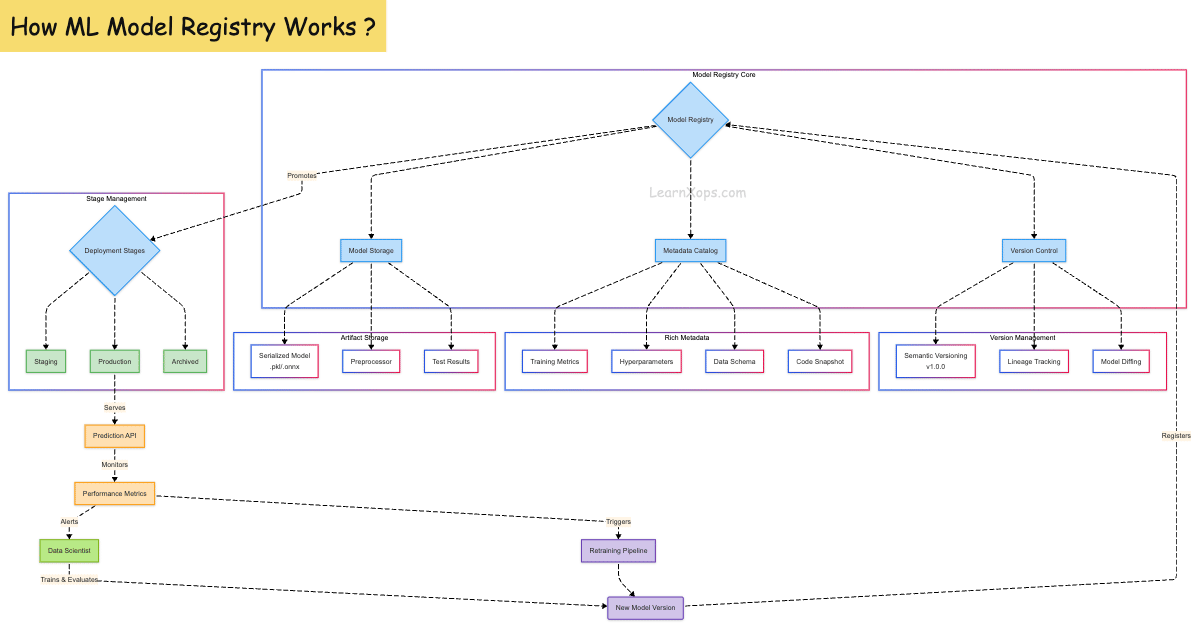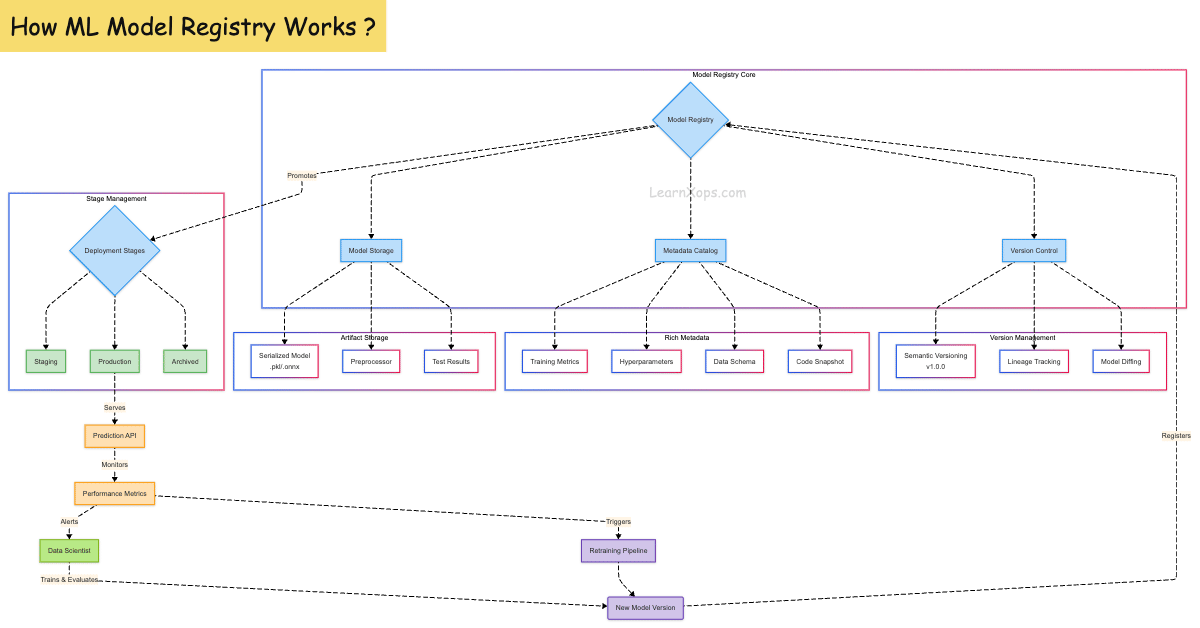
What is Model Registry?
A Model Registry is a centralized hub for managing the lifecycle of machine learning models. It plays a crucial role in tracking, versioning, and deploying models reliably in production environments. Think of it as the equivalent of a source control system for ML models.
Why Use a Model Registry?
- Track multiple versions of a model
- Store metadata (e.g., accuracy, parameters, training dataset)
- Promote models to staging or production
- Enable reproducibility and auditing
- Integrate with CI/CD pipelines for ML
Core Components
| Component | Description |
|---|---|
| Model | Serialized version of the ML model (e.g., .pkl, .onnx) |
| Version | Each model can have multiple versions (v1, v2, etc.) |
| Stage | Lifecycle stage like Staging, Production, Archived |
| Metadata | Info such as metrics, parameters, training date, dataset ID |
| Lineage | Links between training code, data, and model version |
Popular Model Registries
| Tool | Description |
|---|---|
| MLflow | Open-source, part of Databricks ecosystem |
| SageMaker Model Registry | AWS-native managed registry |
| Weights & Biases | Cloud-hosted MLOps platform with model tracking |
| DVC | Git-based model and data versioning |
Example Workflow
- Train a model
- Save the model artifact and metrics
- Register the model to a registry
- Tag it as Staging
- After testing, promote to Production
- Serve it using an inference engine (e.g., FastAPI, TorchServe)
Example Snippet: Using MLflow Registry
import mlflow
# Log model
with mlflow.start_run():
mlflow.sklearn.log_model(model, "model")
mlflow.log_metric("rmse", 0.85)
mlflow.register_model(
"runs:/<run_id>/model",
"ChurnPredictionModel"
)
# Update model stage
from mlflow.tracking import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name="ChurnPredictionModel",
version=1,
stage="Production"
)💡 Pro Tips
- Use naming conventions for models (e.g., project_modelname_vX)
- Automate registry steps via CI/CD pipelines
- Monitor model usage and performance post-deployment
- Archive obsolete or underperforming models
Tracking, Storing, and Versioning Models in the ML Lifecycle
ML Model Lifecycle Stages
- Data Collection & Preprocessing
- Model Training
- Evaluation & Validation
- Versioning & Storage
- Deployment
- Monitoring & Retraining
Model Tracking
Tools
- MLflow Tracking: Logs parameters, metrics, and artifacts
- Weights & Biases: Tracks experiments, datasets, and outputs
- Neptune.ai: Focused on research experiments
What to Track
- Model hyperparameters
- Dataset and feature versions
- Training scripts and environment
- Evaluation metrics
import mlflow
with mlflow.start_run():
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("accuracy", 0.94)
mlflow.log_artifact("model.pkl")Model Storage
Formats
- Pickle (.pkl): Python native format (beware of security risks)
- Joblib: Efficient for numpy arrays
- ONNX: Cross-platform model format
- SavedModel (TensorFlow), TorchScript (PyTorch)
Storage Options
- Cloud Buckets: S3, GCS, Azure Blob
- Model Registries: MLflow, SageMaker, WandB
- Artifact Stores: DVC, Git LFS
Model Versioning
Why Version?
- Ensure reproducibility
- Trace which model was used for a decision
- Compare performance between iterations
- Enable rollbacks
Methods
| Tool | Versioning Strategy |
|---|---|
| MLflow | Auto-versioned runs & models |
| DVC | Git-like version control for models/data |
| SageMaker | Incremental model versions in registry |
| Custom GitOps | Use Git tags/branches for model tracking |
Example: DVC for Model Versioning
# Initialize DVC
$ dvc init
# Track model file
$ dvc add models/model.pkl
# Commit to Git
$ git add models/model.pkl.dvc .gitignore
$ git commit -m "Track model v1 with DVC"
# Push to remote
$ dvc remote add -d myremote s3://ml-models-bucket
$ dvc push🧠 Best Practices
- Always log experiments (code, metrics, data snapshot)
- Store models in reproducible formats
- Automate versioning using pipelines
- Attach metadata like accuracy, dataset ID, git commit hash
Promoting Models Between Stages (e.g., Staging → Production)
Common Stages in Model Lifecycle
| Stage | Purpose |
|---|---|
| None | Initial unassigned stage after registration |
| Staging | Ready for testing and validation by QA or pre-prod environment |
| Production | Approved and live for inference in production environments |
| Archived | Deprecated or superseded models no longer in use |
Workflow: MLflow Model Registry Example
Registering and Promoting a Model
from mlflow.tracking import MlflowClient
client = MlflowClient()
# Register a model version
model_uri = "runs:/<run-id>/model"
model_name = "CreditScoringModel"
mlflow.register_model(model_uri, model_name)
# Promote to Staging
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Staging",
)
# Promote to Production after testing
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Production",
archive_existing_versions=True # Optional: archive older prod models
)Governance Considerations
- Enforce approval gates before production promotion
- Maintain audit logs for transitions
- Use RBAC to control who can promote models
- Define manual vs automated promotion processes
Automation with CI/CD Pipelines
Example CI Step in GitHub Actions
- name: Promote model to Production
run: |
python promote_model.py # Contains MLflow promotion logicTrigger this step after successful staging tests.
Using MLflow, SageMaker, and DVC+Git for Model Registry
MLflow Model Registry
Register and Promote Model
import mlflow
from mlflow.tracking import MlflowClient
# Start an MLflow run and log model
with mlflow.start_run():
mlflow.sklearn.log_model(model, "model")
mlflow.log_metric("accuracy", 0.92)
result = mlflow.register_model(
"runs:/<run_id>/model", "CustomerChurnModel"
)
# Promote model to Production
client = MlflowClient()
client.transition_model_version_stage(
name="CustomerChurnModel",
version=1,
stage="Production",
)SageMaker Model Registry
Register and Deploy Model
import sagemaker
from sagemaker import get_execution_role
from sagemaker.model import Model
role = get_execution_role()
model = Model(
image_uri="123456789012.dkr.ecr.us-west-2.amazonaws.com/my-custom-image:latest",
model_data="s3://my-bucket/model.tar.gz",
role=role
)
# Register Model
model_package_group_name = "CreditScoringModel"
model_package = model.register(
content_types=["application/json"],
response_types=["application/json"],
model_package_group_name=model_package_group_name,
approval_status="PendingManualApproval",
)# Approve to Production manually or via API
sm_client = boto3.client("sagemaker")
sm_client.update_model_package(
ModelPackageArn=model_package.model_package_arn,
ModelApprovalStatus="Approved"
)DVC + Git for Model Versioning
Track and Push Model Artifacts
# Initialize DVC
$ dvc init
# Add model artifact to DVC tracking
$ dvc add models/model.pkl
# Commit and push to Git
$ git add models/model.pkl.dvc .gitignore
$ git commit -m "Track model v1 with DVC"
# Add remote and push model
$ dvc remote add -d myremote s3://my-model-bucket
$ dvc push🔃 Switch Between Versions
# Checkout older Git commit to retrieve old model version
$ git checkout feature/new-model-v2
$ dvc pull # Downloads associated model.pkl🧠 In-Short
| Feature | MLflow | SageMaker | DVC + Git |
|---|---|---|---|
| Model Versioning | ✅ | ✅ | ✅ |
| Promotion Between Stages | ✅ | ✅ | 🚫 (manual via Git) |
| CI/CD Integration | ✅ | ✅ | ✅ |
| Hosted/Cloud Native | Optional | AWS-native | Self-hosted/Git-based |
Each tool has its strengths:
- Use MLflow for flexibility and OSS workflows
- Use SageMaker Registry if you're all-in on AWS
- Use DVC + Git for lightweight, GitOps-style versioning
Pick based on your infra stack, team maturity, and governance needs.
🔥 Challenges
Model Versioning & Tracking
- Register at least 2 versions of the same model (e.g., v1, v2) with different metrics
- Add metadata: model performance, training timestamp, dataset version, and notes
- Compare versions and identify which should go to production
Stage Transition & Promotion
- Promote the best model version from "Staging" → "Production"
- Log the reason for promotion (who approved it, based on what criteria)
Automation Integration
- Add model registration logic to your training script
- Update your serving logic to always fetch the latest "Production" model
Advanced Tracking
- Link each model version with a Git commit hash
- Implement a rollback script that reverts to the last good model version
- Integrate with Slack/Email to notify on model stage changes