 Monitoring ML Systems in Production – Metrics, Logging, Alerting
Monitoring ML Systems in Production – Metrics, Logging, Alerting
Master monitoring to ensure ML models in production are healthy, reliable, and performant. By tracking key metrics, analyzing logs, and setting up alerts, you can proactively detect model drift, data quality issues, and service failures before they impact users.
We must master monitoring to ensure ML models in production are healthy, reliable, and performant. By tracking key metrics, analyzing logs, and setting up alerts, they can proactively detect model drift, data quality issues, and service failures before they impact users.
📚 Key Learnings
- Understand the importance of observability in ML systems: uptime, performance, correctness
- Learn what to monitor: prediction latency, model accuracy, data quality, service health
- Differentiate between system metrics and model metrics
- Set up logging, dashboards, and alerting for deployed ML services
- Use Prometheus, Grafana, and custom logging solutions for insight and traceability
🧠 Learn here
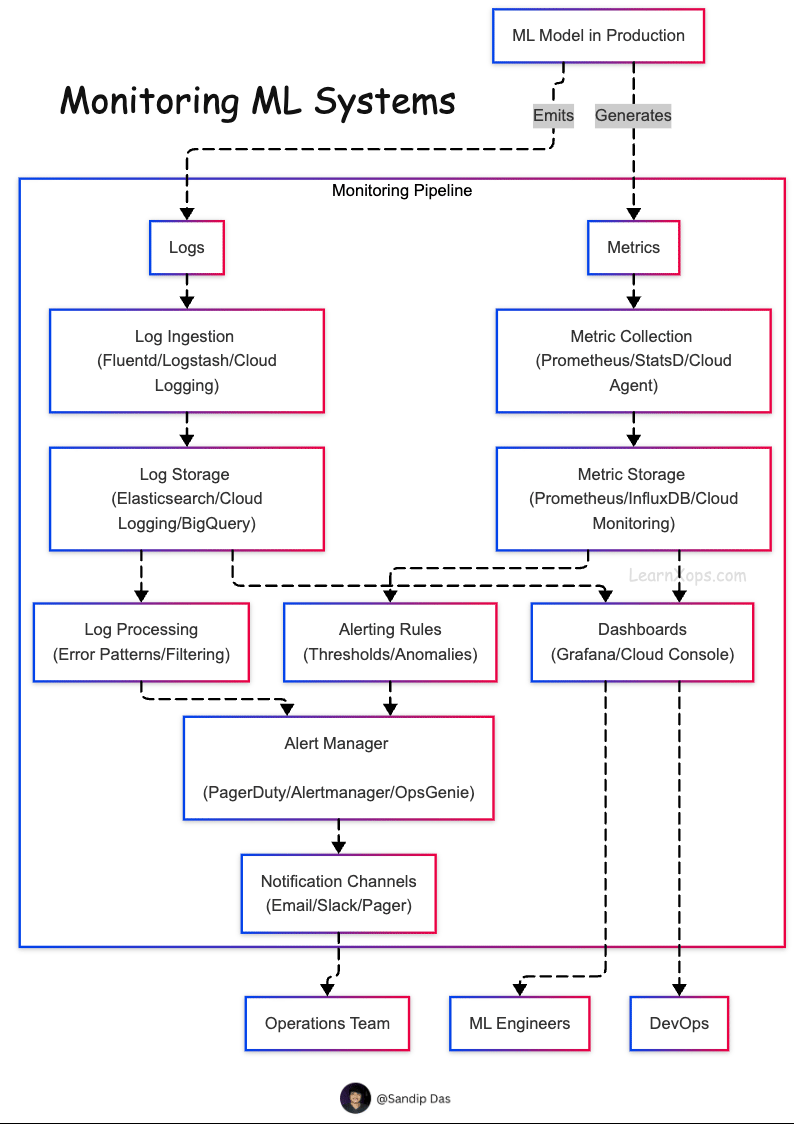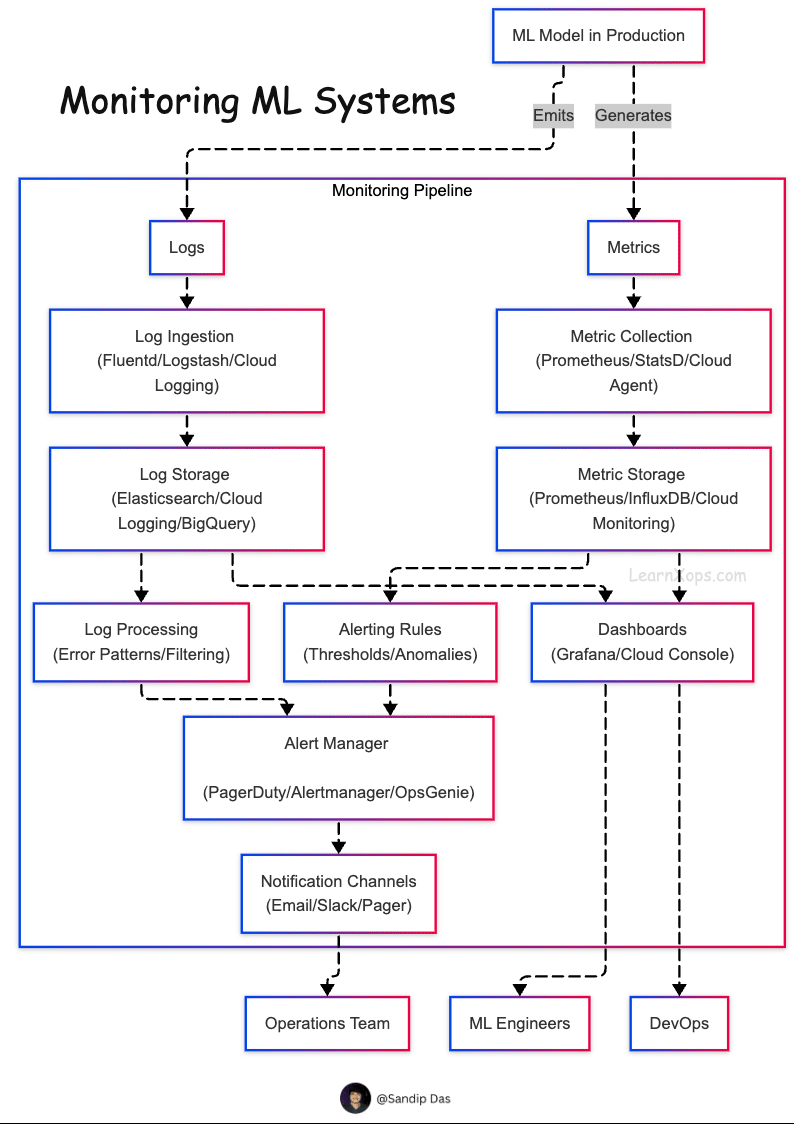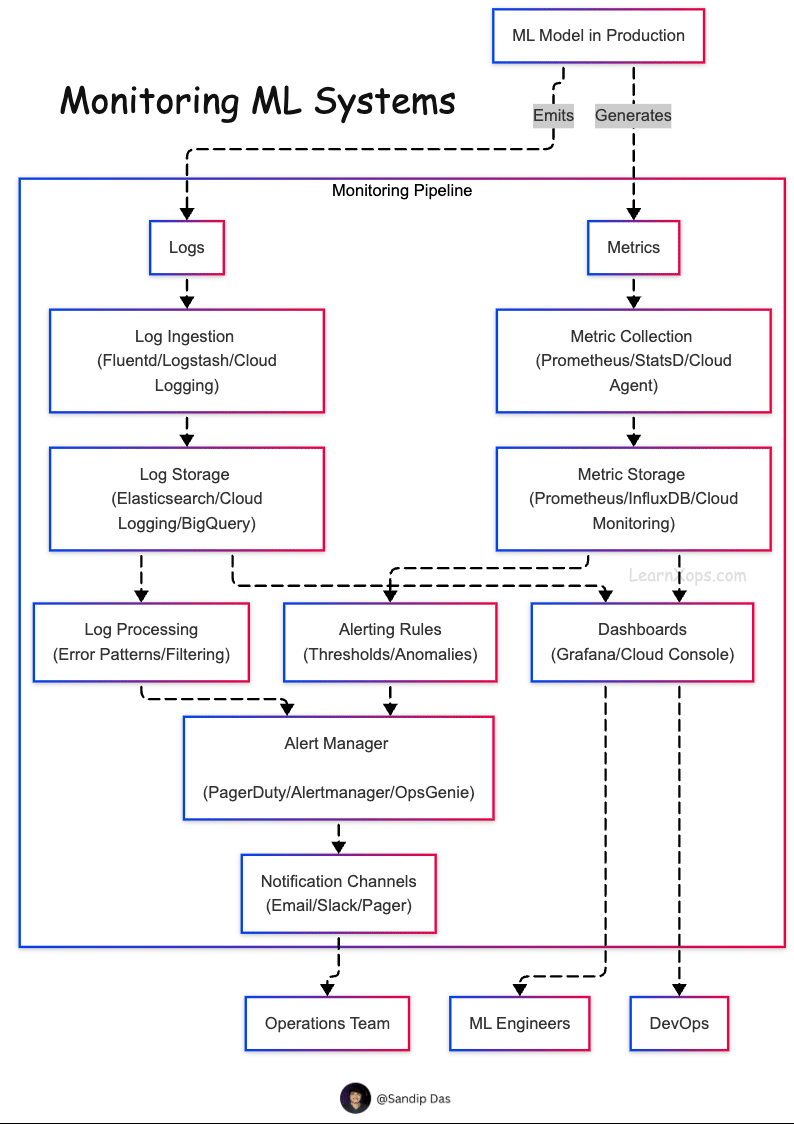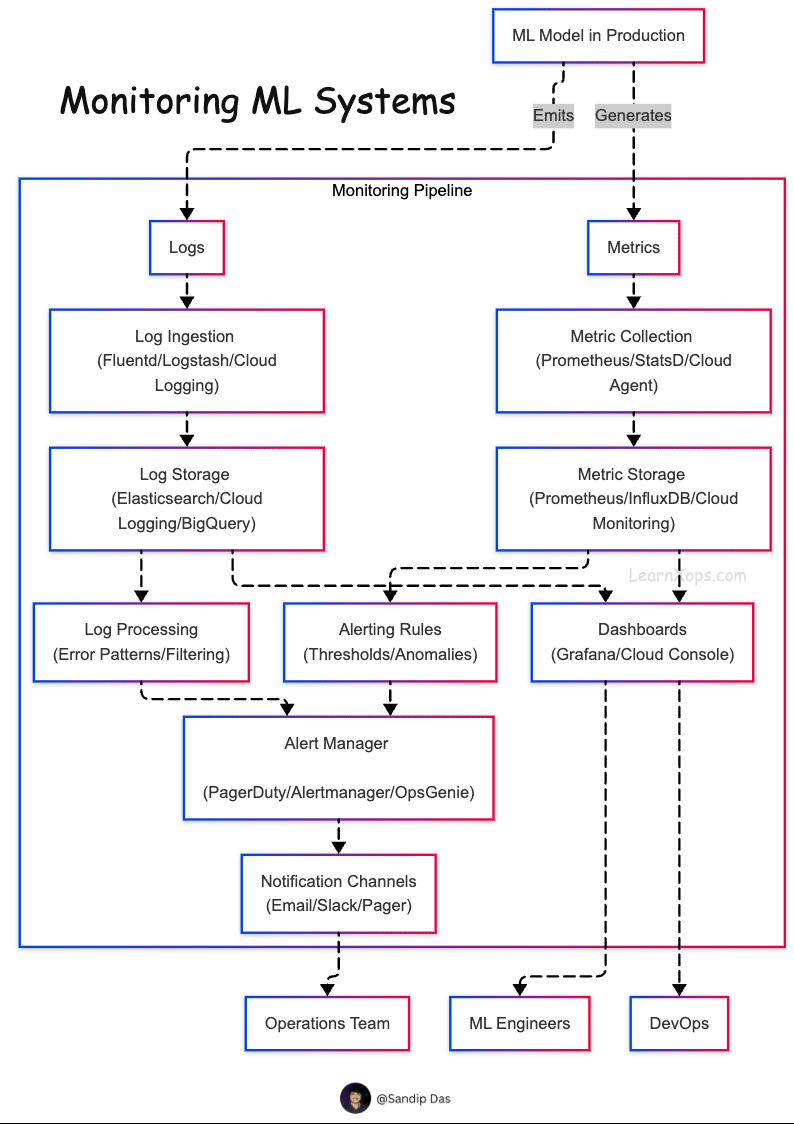
Observability in ML systems is crucial for ensuring that models behave as expected in production. It helps detect issues related to performance, uptime, data quality, drift, and overall system health. Without observability, it's difficult to debug or maintain trust in deployed ML models.
Why Observability Matters in ML
- Uptime: Ensures your model endpoints are live and accessible
- Performance: Tracks latency, throughput, and resource consumption of your ML services
- Correctness: Monitors input/output distributions, predictions, and error rates to catch anomalies or degradation
- Compliance: Supports auditing and governance by keeping a history of inputs, predictions, and model versions
- Root Cause Analysis: Aids debugging of failures, unexpected behaviors, or drifts
Key Observability Metrics
| Category | Metrics |
|---|---|
| System | Uptime, response time, CPU/GPU usage, memory consumption |
| Model | Prediction latency, prediction confidence, accuracy (if feedback exists) |
| Data | Feature distribution, missing/null values, data schema validation |
| Drift | Data drift, concept drift, input/output change rate |
Tools for Observability in ML
- Prometheus + Grafana: For infrastructure and model performance metrics
- OpenTelemetry: Distributed tracing and metrics collection
- EvidentlyAI: Data drift, model performance, and monitoring dashboards
- Seldon Alibi Detect / Fiddler AI / WhyLabs: For advanced monitoring, explainability, and drift detection
- MLflow: Experiment tracking, model versioning, logging parameters and metrics
- Elastic Stack (ELK): Centralized logging and visualization
Best Practices
- Instrument all components: Include data pipeline, model serving layer, and infrastructure
- Set alerts: Define thresholds and set up notifications for anomalies
- Monitor input data: Compare live input features with training data
- Track predictions: Log and analyze prediction confidence and output distribution
- Version control everything: Track changes in code, models, and data schemas
Example Metrics to Track in Production
- Model response time > 300ms
- Drift in feature user_age > 10% from training distribution
- Model confidence < 0.5 for more than 5% of predictions
- Increase in null/missing values in real-time data > 2%
ML Monitoring: What to Monitor?
1. Prediction Latency
Latency indicates the time taken to serve a prediction request. High latency affects user experience and system performance.
Example: FastAPI + Prometheus
from fastapi import FastAPI, Request
import time
from prometheus_client import Histogram, start_http_server
app = FastAPI()
REQUEST_LATENCY = Histogram('prediction_latency_seconds', 'Time for prediction', ['endpoint'])
@app.post("/predict")
async def predict(request: Request):
start_time = time.time()
# simulate prediction
time.sleep(0.3) # replace with actual model.predict()
latency = time.time() - start_time
REQUEST_LATENCY.labels(endpoint="/predict").observe(latency)
return {"prediction": 42}
# Start Prometheus metrics server
start_http_server(8001)2. Model Accuracy (Offline Evaluation)
Use actual labels after feedback to compare predictions and evaluate accuracy.
Example: with Scikit-Learn
from sklearn.metrics import accuracy_score
import pandas as pd
# Simulated predictions and actuals
preds = [1, 0, 1, 1, 0]
y_true = [1, 0, 0, 1, 0]
accuracy = accuracy_score(y_true, preds)
print(f"Accuracy: {accuracy * 100:.2f}%")In production, log and evaluate this periodically using feedback labels.
3. Data Quality
Check for missing values, type mismatches, or invalid ranges in live input data.
Example: Real-Time Data Checks
import pandas as pd
def validate_data(df):
issues = {}
if df.isnull().sum().any():
issues['nulls'] = df.isnull().sum().to_dict()
if (df['age'] < 0).any():
issues['age_range'] = "Negative age found"
if df['salary'].dtype != float:
issues['salary_type'] = "Expected float for salary"
return issues
# Example incoming request payload
data = pd.DataFrame({"age": [25, -1], "salary": [50000, "unknown"]})
print(validate_data(data))4. Service Health
Check uptime, HTTP error codes, memory/CPU usage, etc.
Example: FastAPI + Prometheus Metrics
from prometheus_client import Counter
REQUEST_COUNT = Counter('request_count', 'App Request Count', ['method', 'endpoint'])
ERROR_COUNT = Counter('error_count', 'Error Count', ['method', 'endpoint'])
@app.middleware("http")
async def count_requests(request: Request, call_next):
method = request.method
endpoint = request.url.path
REQUEST_COUNT.labels(method=method, endpoint=endpoint).inc()
try:
response = await call_next(request)
except Exception:
ERROR_COUNT.labels(method=method, endpoint=endpoint).inc()
raise
return responseUse tools like Grafana to visualize the metrics.
Recommended Tools:
- Prometheus + Grafana for latency and health metrics
- MLflow or custom DB to store prediction vs actuals
- EvidentlyAI for data quality and drift detection
- OpenTelemetry for tracing
✅ Pro Tips:
- Always define thresholds and alerting rules
- Track metrics at both infra (CPU, memory) and model levels
- Monitor data inputs continuously to prevent garbage-in garbage-out
- Monitoring = Observability + Actionable Insights
System Metrics vs Model Metrics
System metrics focus on infrastructure performance, while model metrics focus on model behavior and outcomes.
Understanding the difference between system and model metrics is crucial for building and maintaining reliable ML systems in production.
| Aspect | System Metrics | Model Metrics |
|---|---|---|
| Definition | Metrics related to infrastructure and application performance | Metrics that evaluate ML model behavior and performance |
| Focus Area | Hardware, network, service uptime | Prediction quality, fairness, drift, and model reliability |
| Examples | CPU usage, memory, disk I/O, network latency, HTTP errors | Accuracy, precision, recall, AUC, prediction latency, drift |
| Collection Tools | Prometheus, Grafana, Datadog, CloudWatch | MLflow, EvidentlyAI, custom logging, Alibi Detect |
| Usage | Ensures system availability and performance | Ensures model is accurate, fair, and not degrading |
| Alert Triggers | High CPU/memory, service down, HTTP 500 errors | High prediction errors, drift detected, confidence drop |
| Visualization | System dashboards (Grafana, Cloud dashboards) | ML dashboards (Evidently, custom visualizations) |
| Granularity | Service-level or node-level | Feature-level or prediction-level |
| Who Monitors | DevOps, SREs | ML Engineers, Data Scientists |
Both metric types are essential for a robust and reliable ML system in production.
Logging, Dashboards, and Alerting for Deployed ML Services
These components are critical for production readiness, troubleshooting, and operational excellence.
1. Logging
Logging is essential for capturing runtime behavior, inputs/outputs, and model predictions for debugging and auditing.
Example: Logging in FastAPI ML Endpoint
from fastapi import FastAPI, Request
import logging
# Configure logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
app = FastAPI()
@app.post("/predict")
async def predict(request: Request):
payload = await request.json()
logging.info(f"Received input: {payload}")
result = {"prediction": 1} # Simulated prediction
logging.info(f"Prediction result: {result}")
return resultTip: Use structured logging (e.g., JSON logs) for better parsing in tools like ELK or Datadog.
2. Dashboards
Dashboards provide visual insights into system health, prediction quality, latency, and data distribution.
Example: Prometheus + Grafana Setup for ML Service
Expose metrics in FastAPI
from prometheus_client import start_http_server, Summary
PREDICTION_TIME = Summary('prediction_time_seconds', 'Time spent making prediction')
@PREDICTION_TIME.time()
@app.post("/predict")
async def predict(request: Request):
# Simulated logic
return {"prediction": 1}
start_http_server(8001) # Expose metrics at :8001/metricsGrafana Dashboard Panels:
- Model prediction latency (from
prediction_time_seconds) - Number of requests
- Error rates
- CPU/memory usage
Use labels to filter metrics by endpoint, model version, or feature.
3. Alerting
Alerts notify you when things go wrong or deviate from expected behavior.
Example: Prometheus Alert Rules
groups:
- name: ml-service-alerts
rules:
- alert: HighLatency
expr: prediction_time_seconds_sum / prediction_time_seconds_count > 1
for: 2m
labels:
severity: warning
annotations:
summary: "High prediction latency detected"
- alert: RequestFailures
expr: increase(http_requests_total{status="500"}[5m]) > 5
for: 1m
labels:
severity: critical
annotations:
summary: "High number of 500 errors"Alerting Integrations
- Email / Slack / Teams (via Alertmanager)
- PagerDuty / Opsgenie for on-call management
Always include summary and description in alerts for quick troubleshooting.
Recommended Tool Stack
| Purpose | Tools |
|---|---|
| Logging | Python Logging, FluentBit, ELK, Loki |
| Metrics | Prometheus, OpenTelemetry |
| Dashboards | Grafana, Kibana |
| Alerting | Prometheus Alertmanager, PagerDuty |
Insight and Traceability with Prometheus, Grafana, and Custom Logging
Let's understand how to implement insight and traceability in ML services using Prometheus, Grafana, and custom logging with a FastAPI-based model serving app.
🧠 Objective
To gain deep observability into:
- Prediction latency
- Request volumes and failures
- Runtime logs for input/output tracing
- Real-time dashboards for alerting and troubleshooting
Stack Overview
| Component | Tool |
|---|---|
| Metrics | Prometheus |
| Visualization | Grafana |
| Logging | Python Logging + Fluent Bit (optional) |
| App Framework | FastAPI |
Step 1: FastAPI App with Prometheus Metrics & Logging
main.py
from fastapi import FastAPI, Request
from prometheus_client import Counter, Summary, make_asgi_app
import time
import logging
# Setup Logging
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
# Metrics
REQUEST_COUNT = Counter("request_count", "Total request count", ['method', 'endpoint'])
PREDICTION_LATENCY = Summary("prediction_latency_seconds", "Prediction latency in seconds")
# FastAPI app
app = FastAPI()
metrics_app = make_asgi_app()
app.mount("/metrics", metrics_app)
@app.middleware("http")
async def record_metrics(request: Request, call_next):
method = request.method
endpoint = request.url.path
REQUEST_COUNT.labels(method=method, endpoint=endpoint).inc()
start_time = time.time()
response = await call_next(request)
latency = time.time() - start_time
PREDICTION_LATENCY.observe(latency)
return response
@app.post("/predict")
@PREDICTION_LATENCY.time()
async def predict(request: Request):
payload = await request.json()
logging.info(f"Incoming payload: {payload}")
prediction = {"result": 1} # Dummy model
logging.info(f"Prediction: {prediction}")
return predictionStep 2: Run Prometheus
prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'fastapi-app'
static_configs:
- targets: ['localhost:8000']Start Prometheus
prometheus --config.file=prometheus.ymlStep 3: Set Up Grafana Dashboard
- Run Grafana:
docker run -d -p 3000:3000 grafana/grafana - Add Prometheus as a data source (URL:
http://host.docker.internal:9090) - Create panels for:
request_countprediction_latency_seconds
🧠 You can import a JSON dashboard config or create visual alerts from panels.
Step 4: Custom Logging with Fluent Bit
If using containers, route logs to Elastic or Loki for full observability.
Example: Log to File (Basic)
uvicorn main:app --host 0.0.0.0 --port 8000 --log-config log_config.yamlSample log_config.yaml
version: 1
formatters:
default:
format: '%(asctime)s - %(levelname)s - %(message)s'
handlers:
file:
class: logging.FileHandler
filename: logs/app.log
formatter: default
root:
level: INFO
handlers: [file]🧠 Expected Outcome
With the above setup, you get:
- Real-time metrics scraped by Prometheus
- Visual dashboards via Grafana
- Logged inputs/outputs for traceability
- Alert conditions (high latency, error rate) visible in Grafana
This setup ensures production-grade observability for your ML services. Enhance further by adding tracing (e.g., OpenTelemetry) and distributed log collectors (Fluent Bit, Logstash).
🔥 Challenges
Instrumentation
- Add a metrics endpoint (e.g., /metrics) to your FastAPI/Flask app
- Track and expose latency of each prediction
- Log every request and response in a file or stdout
Monitoring Setup
- Install and configure Prometheus to collect app metrics
- Connect Grafana to Prometheus and build a dashboard
- Monitor system-level metrics like CPU, memory via node_exporter
Alerting
- Set up a rule: Alert if avg latency > 500ms for 5 mins
- Send alert to Slack/email (use Alertmanager or a webhook tool)
Advanced
- Use EvidentlyAI or WhyLabs to log and visualize prediction distributions
- Implement trace IDs for incoming requests to correlate logs and metrics