30 Days of MLOps Challenge · Day 8
 Model Evaluation & Metrics – Measure What Matters
Model Evaluation & Metrics – Measure What Matters
Measure what matters to ensure your models perform reliably in the real world. Pick the right metrics, visualize results, and keep evaluation consistent from training to production.
💡 Hey — It's Aviraj Kawade 👋
Key Learnings
- Why evaluation metrics are critical to assess ML model performance.
- Core classification metrics: Accuracy, Precision, Recall, F1-Score, ROC-AUC, Confusion Matrix.
- Difference between classification and regression metrics.
- Understand Precision–Recall tradeoff and when to use which metric.
- Visual tools to interpret performance (ROC, PR curve, confusion matrix heatmap).
- Importance of evaluation consistency during training and deployment.
ML Evaluation Metrics
Evaluation metrics are quantitative measures of model quality. Choose metrics by task: classification, regression, or clustering. Always align metric choice with the business cost of errors.
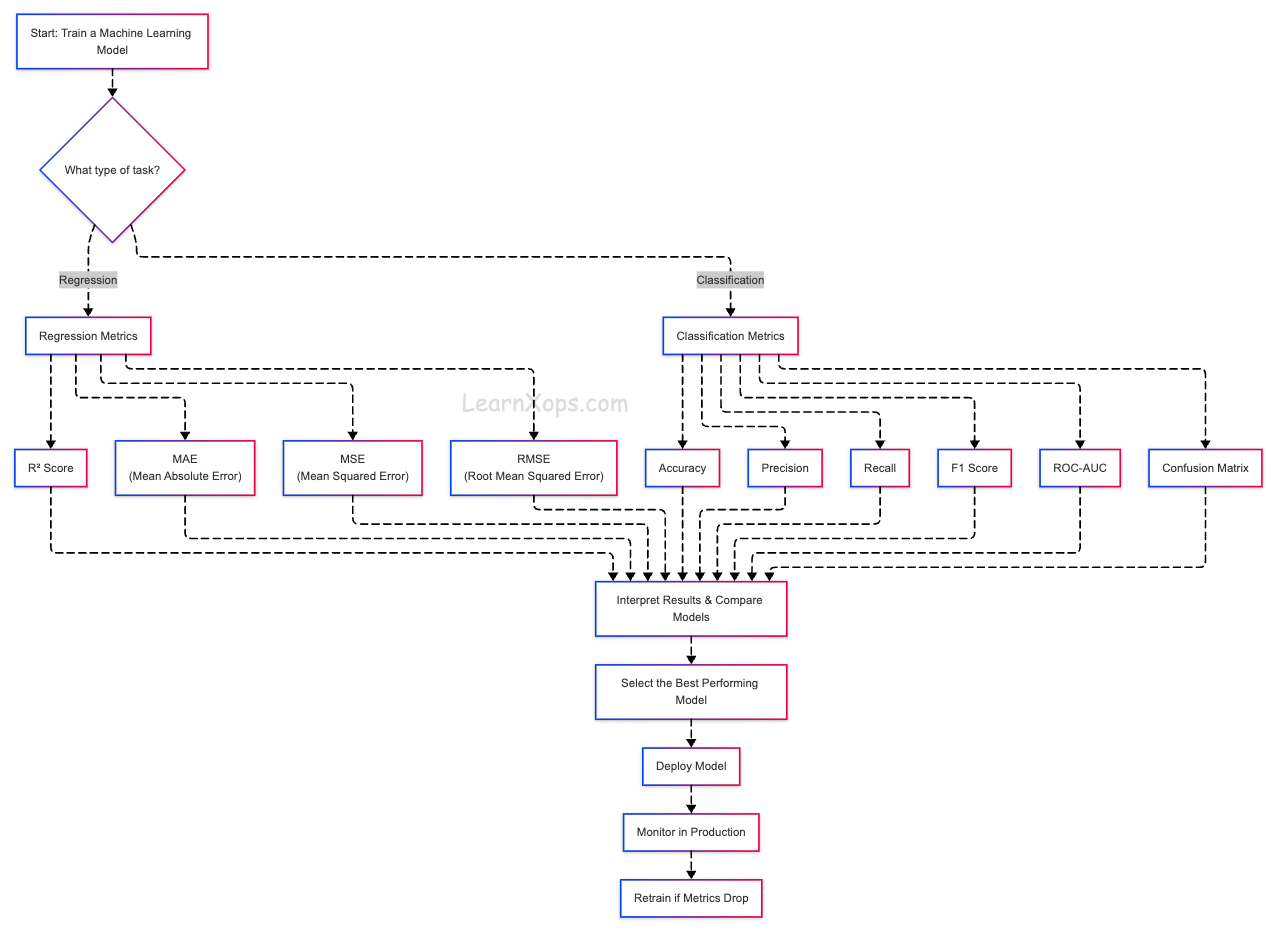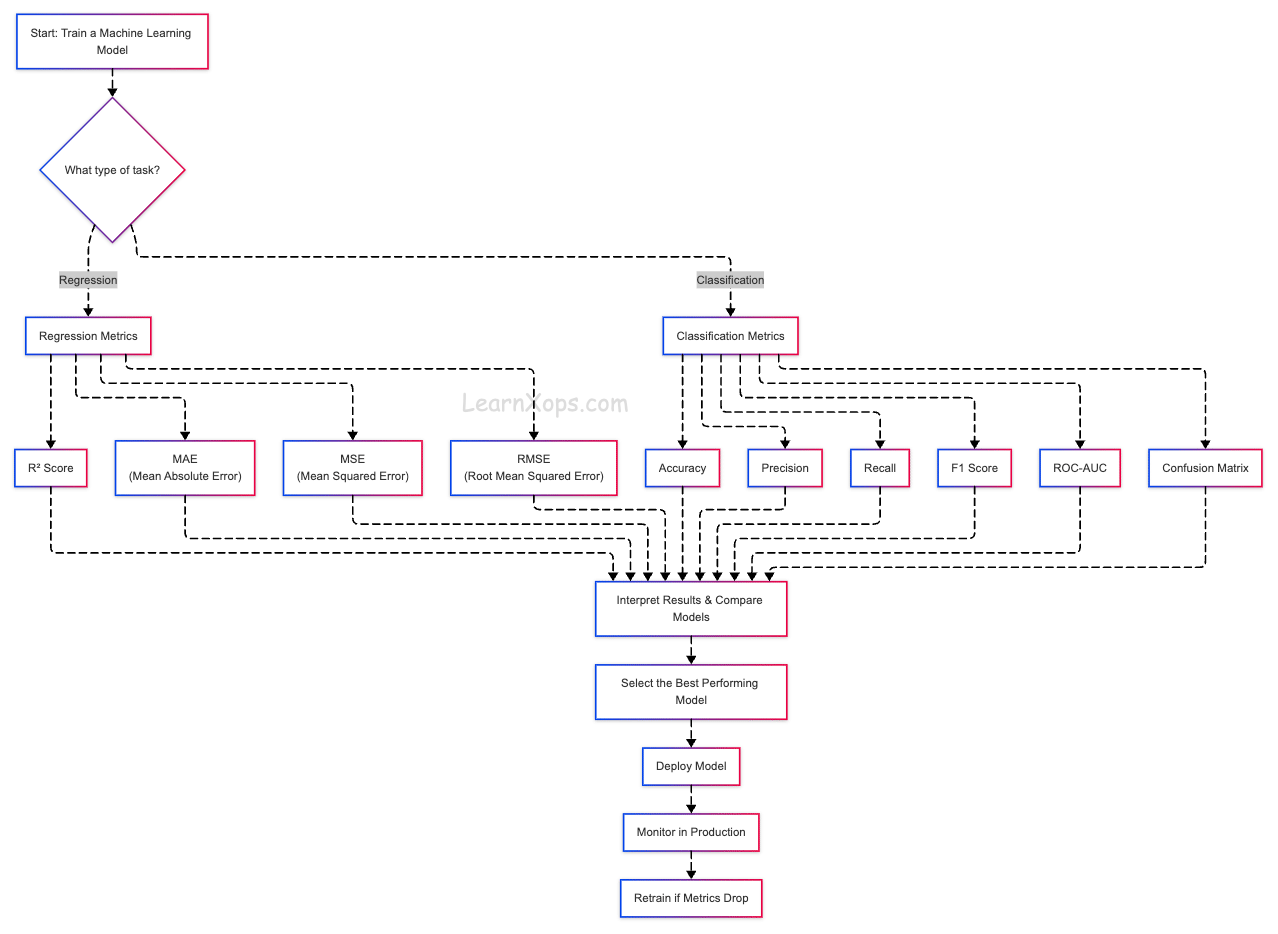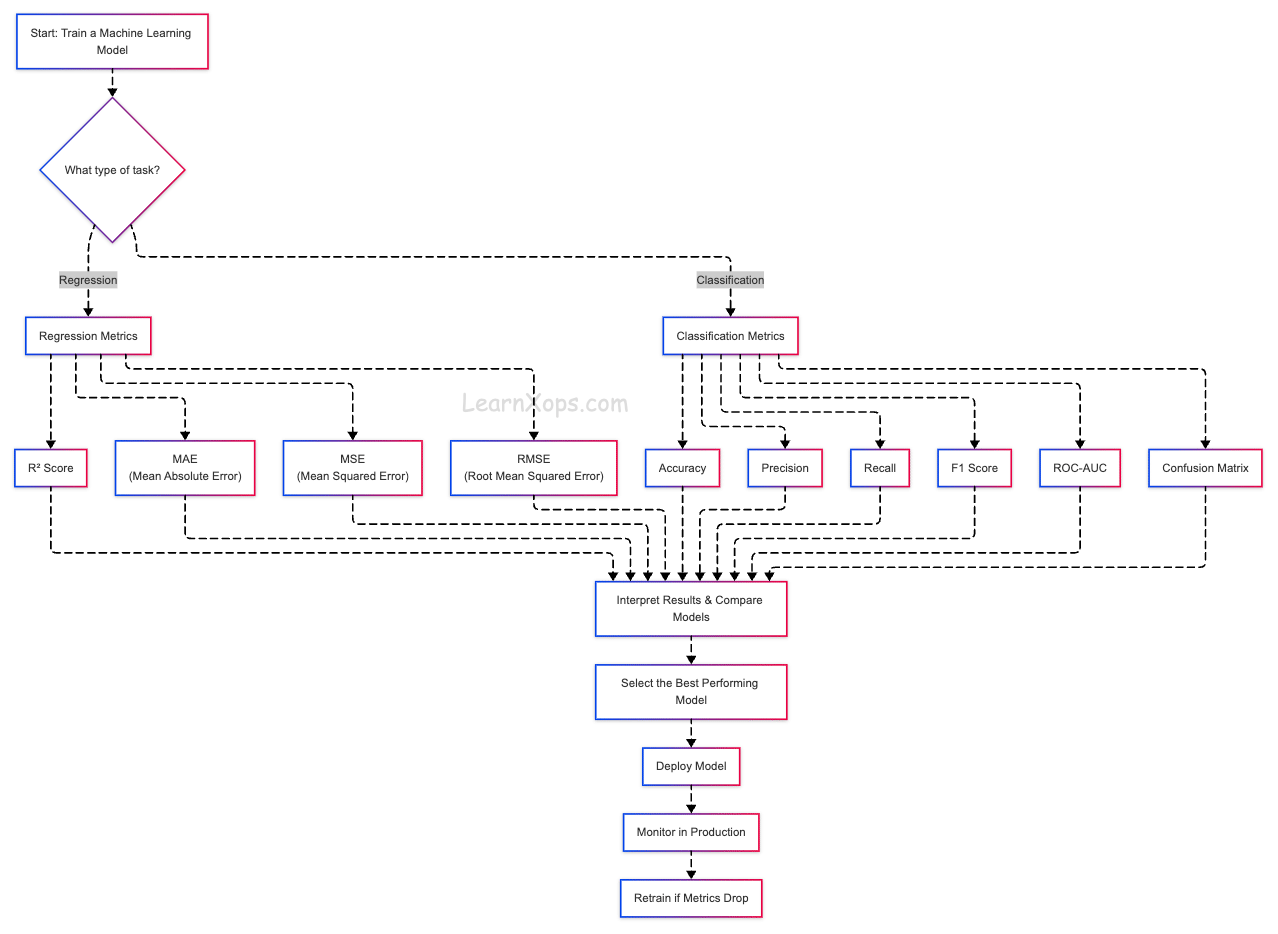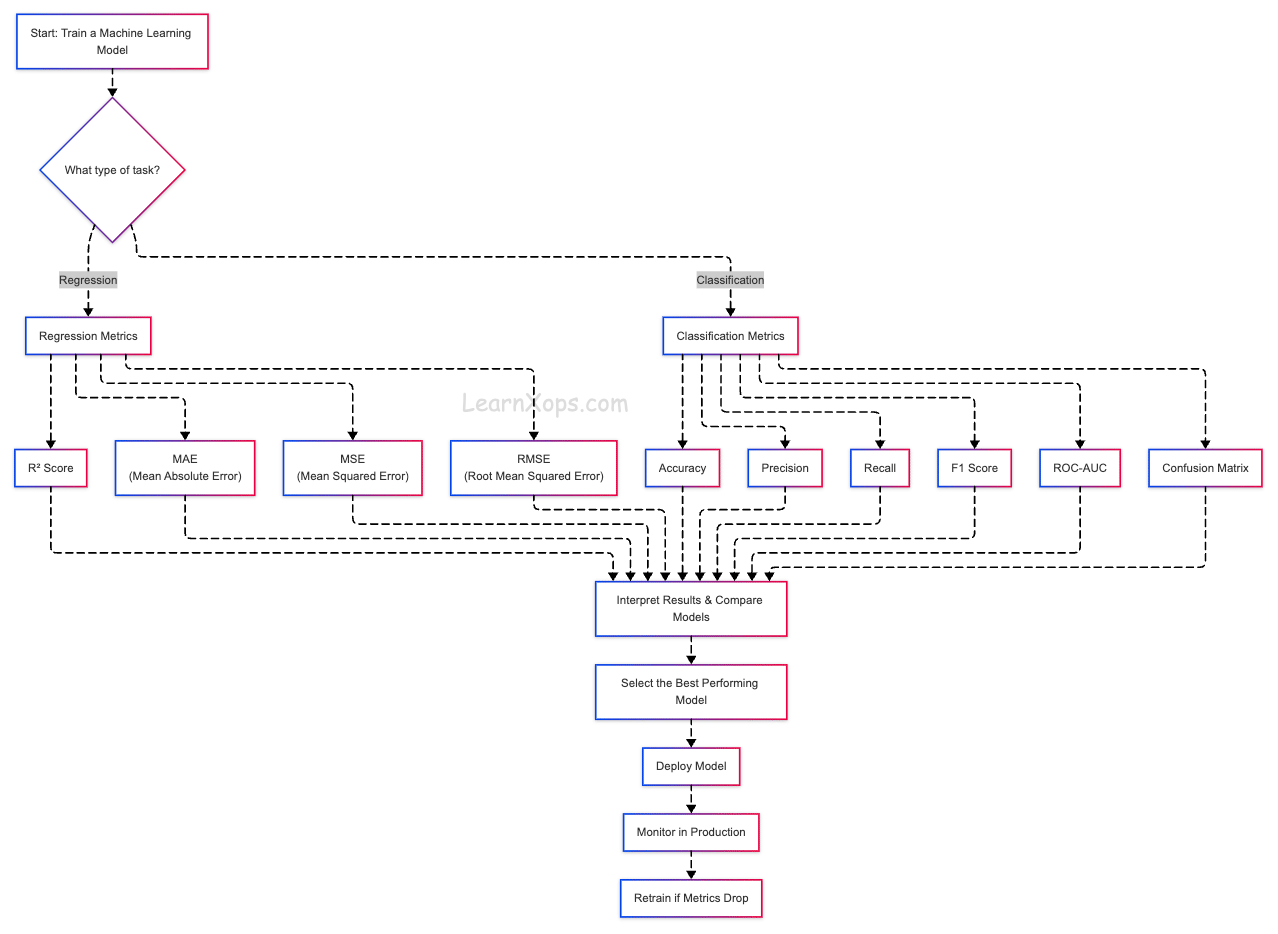
Classification Metrics
| Metric | Description |
|---|---|
| Accuracy | Ratio of correct predictions to total predictions. |
| Precision | TP / (TP + FP). Controls false positives. |
| Recall (Sensitivity) | TP / (TP + FN). Controls false negatives. |
| F1 Score | Harmonic mean of precision and recall. Good for imbalance. |
| ROC‑AUC | Area under ROC curve; threshold‑independent separability. |
| Confusion Matrix | TP/FP/TN/FN grid; visualizes types of errors. |
Regression & Clustering
| Regression Metric | Description |
|---|---|
| MAE | Mean absolute error; robust to outliers. |
| MSE | Mean squared error; penalizes large errors more. |
| RMSE | Square root of MSE; same units as target. |
| R² | Explained variance (1 is perfect fit). |
| Clustering Metric | Description |
|---|---|
| Silhouette | Similarity to own cluster vs nearest other cluster. |
| Adjusted Rand Index | Agreement between predicted and true clusters. |
| Davies–Bouldin | Lower is better; intra/inter‑cluster ratio. |
Why Metrics Matter
| Role | Explanation |
|---|---|
| Model Selection | Compare candidates on the same yardstick. |
| Hyperparameter Tuning | Optimize toward the right objective. |
| Monitoring in Production | Track quality over time; catch regressions. |
| Bias Detection | Reveal fairness and imbalance issues. |
| Business Impact | Link model behavior to real costs/benefits. |
Example: Fraud detection with 2% positives: 98% accuracy can still miss all fraud. Prefer precision/recall/F1 and ROC‑AUC over raw accuracy.
Binary Classification: Quick Formulas
| Metric | Formula | Use When |
|---|---|---|
| Precision | TP / (TP + FP) | False positives are costly (e.g., spam). |
| Recall | TP / (TP + FN) | Missing positives is risky (e.g., cancer). |
| F1 | 2·(P·R)/(P+R) | Balanced view on imbalanced data. |
| ROC‑AUC | Area under ROC | Threshold‑free separability. |
| Confusion Matrix | TP/FP/TN/FN | Error analysis by type. |
Scikit‑learn Snippet
from sklearn.metrics import classification_report, confusion_matrix
y_true = [0, 1, 1, 1, 0, 1, 0, 0, 1, 0]
y_pred = [0, 1, 0, 1, 0, 0, 0, 1, 1, 0]
print(confusion_matrix(y_true, y_pred))
print(classification_report(y_true, y_pred))
Classification vs Regression
| Feature | Classification | Regression |
|---|---|---|
| Goal | Discrete class prediction | Continuous value prediction |
| Common Metrics | Accuracy, Precision, Recall, F1, ROC‑AUC | MAE, MSE, RMSE, R² |
| Output | Labels (e.g., Spam/Not) | Real numbers (e.g., price) |
| Imbalance Handling | Use P/R/F1, PR curve | N/A (not typical) |
| Visuals | ROC, PR, Confusion Matrix | Residuals, ŷ vs y |
Precision–Recall Tradeoff
- Higher precision usually lowers recall, and vice‑versa.
- Conservative threshold → ↑Precision, ↓Recall; inclusive threshold → ↑Recall, ↓Precision.
- Use PR curve on imbalanced data; prefer F1 to balance P/R.
- Choose threshold based on business costs (false +/−).
F1 = 2 · (Precision · Recall) / (Precision + Recall)
| Scenario | Prefer | Why |
|---|---|---|
| Spam Detection | Precision | False positives annoy users. |
| Cancer Diagnosis | Recall | False negatives are dangerous. |
| Search Ranking | Precision | Top results must be relevant. |
| Fraud Detection | Recall | Catch as many frauds as possible. |
Visual Tools
- ROC Curve: TPR vs FPR across thresholds; AUC summarizes performance. Best with balanced classes.
- PR Curve: Precision vs Recall; better for imbalanced data.
- Confusion Matrix Heatmap: Visualizes TP/FP/TN/FN to spot error patterns.
Consistency from Train → Prod
- Use the same preprocessing at training and inference.
- Keep identical metrics and evaluation code in both stages.
- Version artifacts and evaluation scripts; enable reproducibility.
- Monitor drift and performance over time; alert on drops.
- Maintain audit trails for regulated environments.
Try it: Binary Classification (Titanic)
- Install
pip install scikit-learn matplotlib seaborn pandas - Load & preprocess
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler df = pd.read_csv('train.csv') X = df[['Pclass', 'Age', 'SibSp', 'Fare']].fillna(df.mean(numeric_only=True)) y = df['Survived'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) - Train
from sklearn.linear_model import LogisticRegression model = LogisticRegression(max_iter=1000) model.fit(X_train, y_train) - Evaluate
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, roc_auc_score y_pred = model.predict(X_test) y_prob = model.predict_proba(X_test)[:, 1] print("Accuracy:", accuracy_score(y_test, y_pred)) print("Precision:", precision_score(y_test, y_pred)) print("Recall:", recall_score(y_test, y_pred)) print("F1 Score:", f1_score(y_test, y_pred)) print("ROC AUC:", roc_auc_score(y_test, y_prob)) - Visualize
import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import roc_curve cm = confusion_matrix(y_test, y_pred) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.title('Confusion Matrix') plt.xlabel('Predicted') plt.ylabel('Actual') plt.show() fpr, tpr, _ = roc_curve(y_test, y_prob) plt.plot(fpr, tpr, label='Logistic Regression') plt.plot([0, 1], [0, 1], 'k--') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('ROC Curve') plt.legend() plt.show()
Challenges
- Train a binary classifier and report 5+ classification metrics.
- Plot a confusion matrix heatmap with seaborn.heatmap().
- Plot ROC curve and compute AUC.
- Evaluate on an imbalanced subset using Precision, Recall, and F1.
- Compare 2 models (e.g., Logistic Regression vs Random Forest).
- Document the best metric for your use case and why.
- Save results to JSON/CSV and log to MLflow or W&B.