 ML Pipelines with Kubeflow Pipelines – Automate & Orchestrate ML Workflows
ML Pipelines with Kubeflow Pipelines – Automate & Orchestrate ML Workflows
Automate and orchestrate complex ML workflows with Kubeflow Pipelines on Kubernetes for consistency, reproducibility, and scale.
Key Learnings
- Why ML pipelines are essential in production ML workflows.
- What orchestration is and why DAGs matter.
- Kubeflow Pipelines for building and managing ML workflows.
- Step‑based (Airflow) vs component‑based (Kubeflow) workflows.
- Install Kubeflow and run a simple pipeline.
What are ML Pipelines?
ML pipelines are structured workflows that automate and streamline model development, deployment, and maintenance.
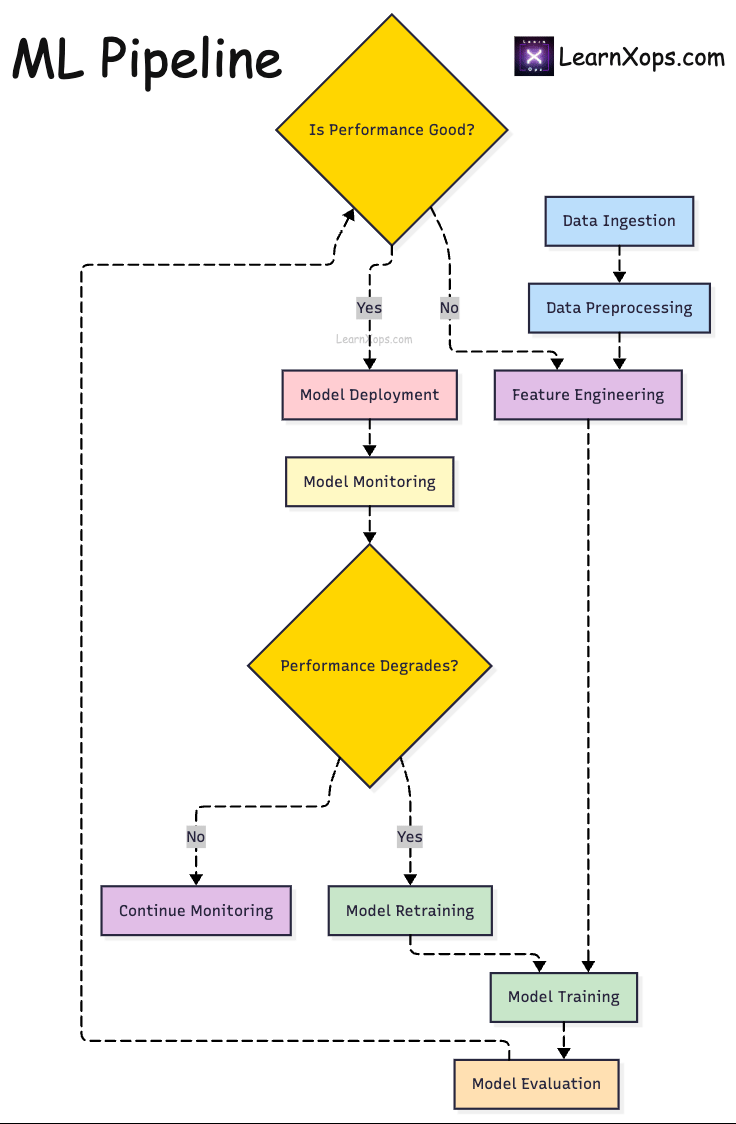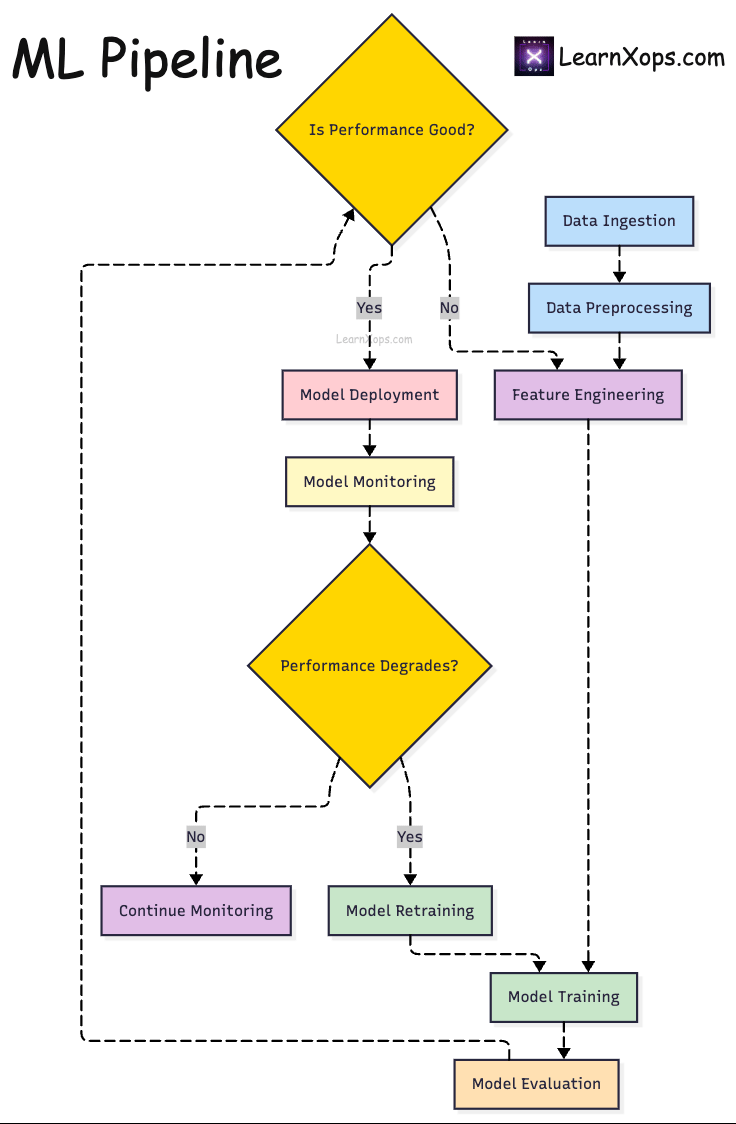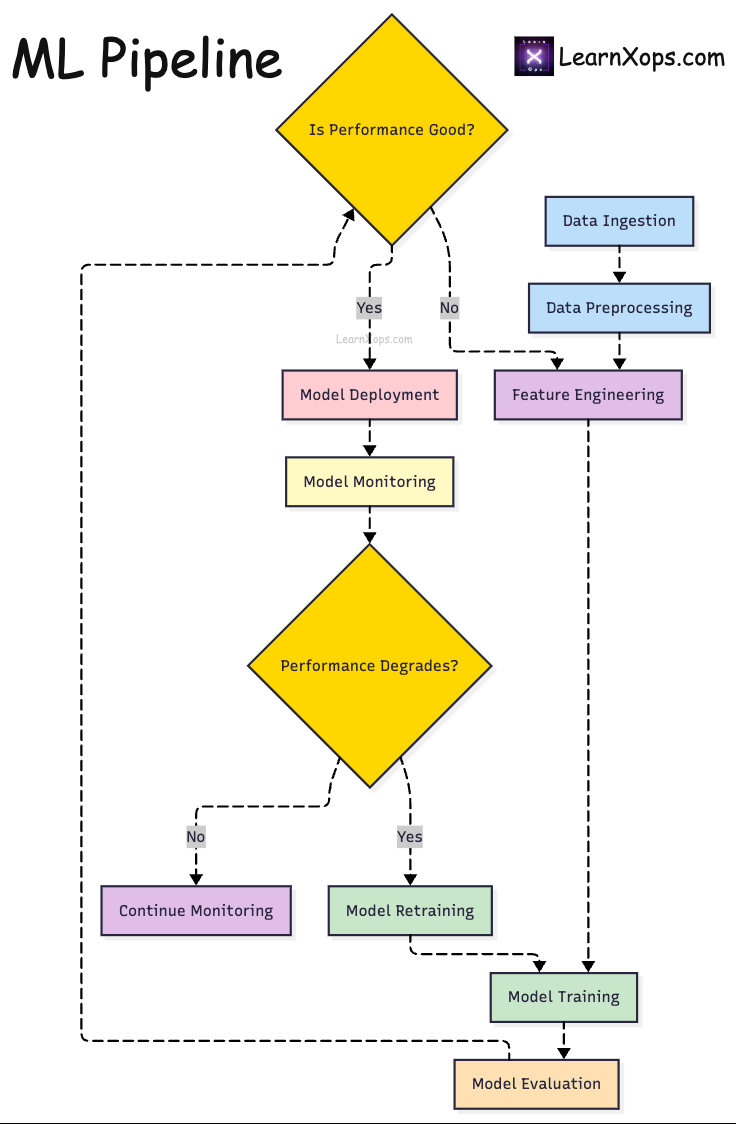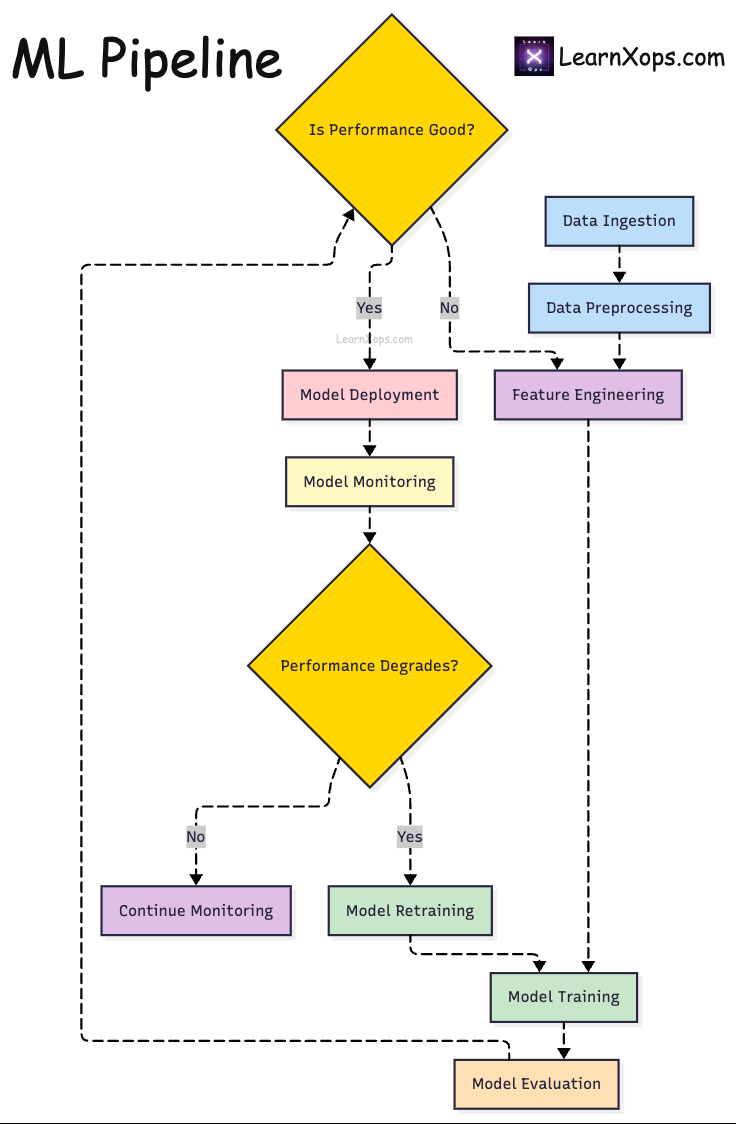
Core Stages
| Stage | Description |
|---|---|
| 1. Data Ingestion | Collect from APIs, DBs, files. |
| 2. Preprocessing | Clean, normalize, transform. |
| 3. Feature Engineering | Create/select features. |
| 4. Training | Train models on processed data. |
| 5. Evaluation | Validate with metrics. |
| 6. Deployment | Serve via APIs, batch, edge. |
| 7. Monitoring | Track perf, drift, errors. |
| 8. Retraining | Refresh models with new data. |
Why Pipelines?
- Automation and reduced toil.
- Reproducibility and versioning.
- Scalability across data/environments.
- Collaboration via modular steps.
Tools
| Tool | Purpose |
|---|---|
| Scikit‑learn Pipelines | Lightweight in‑process pipelines. |
| Kubeflow Pipelines | K8s‑native ML workflows. |
| Apache Airflow | General orchestration (ETL, ML). |
| MLflow | Experiment tracking & lifecycle. |
| Feast/Tecton | Feature store integration. |
| TFX | Production‑grade ML pipelines. |
Orchestration & DAGs
Orchestration coordinates tasks with order, dependencies, retries, and efficient resource use. DAGs define nodes (tasks) with directed, acyclic edges.
- Manage execution order
- Reuse components and cache results
- Visualize flow in UI
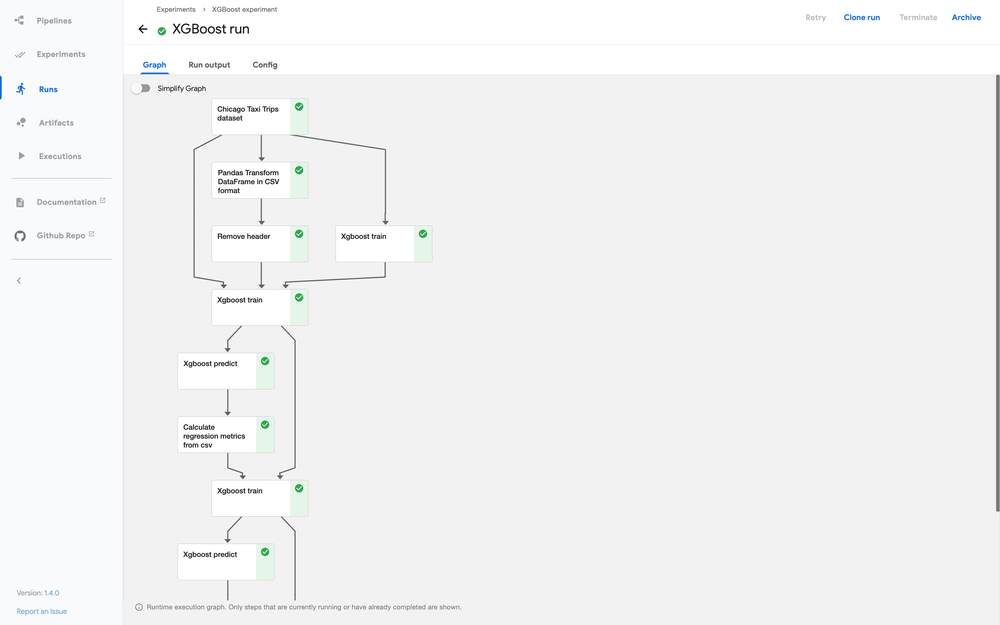
Why DAGs Matter
| Reason | Description |
|---|---|
| Order | Tasks run in a defined sequence. |
| Dependencies | Clear upstream/downstream. |
| Parallelism | Independent tasks run together. |
| Failure Isolation | Retry/skip without global failure. |
| Reusability | Version and reuse DAGs. |
| Auditability | Visualize and trace lineage. |
Kubeflow in a Nutshell
Kubeflow = Kubernetes + ML Workflows. An open‑source platform to build, deploy, and scale ML on K8s.
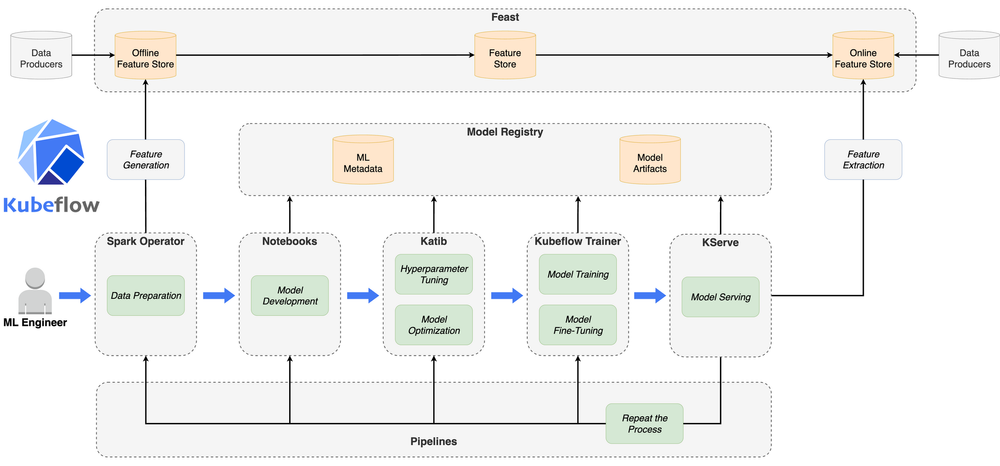
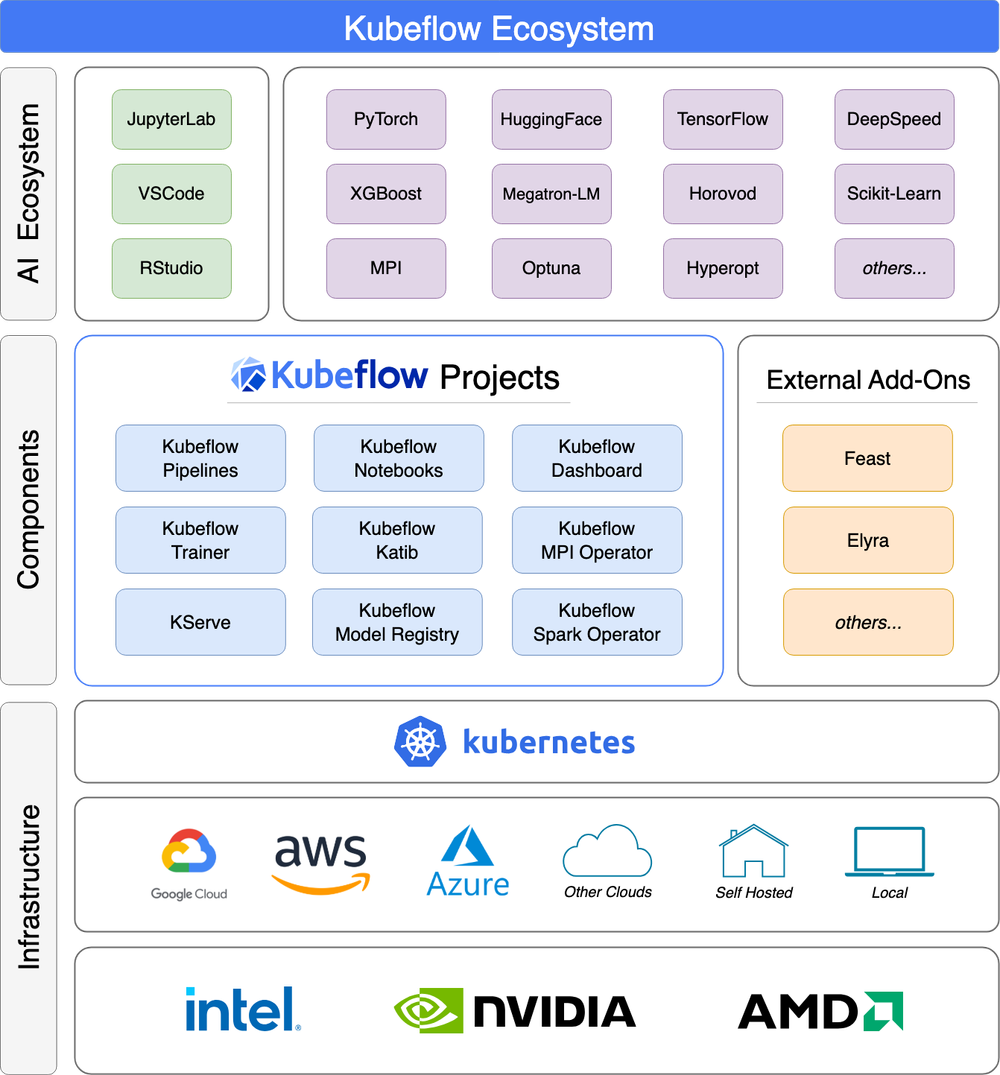
Kubeflow Concepts & Components
- Kubeflow Pipelines: UI + SDK for DAGs.
- Katib: AutoML and HPO.
- KServe: Model serving on Knative.
- Notebooks: Jupyter on K8s.
- Training Operators: TFJob, PyTorchJob, XGBoostJob, MPIJob.
- Central Dashboard: Entry to all services.
- Profiles & RBAC: Multi‑tenancy isolation.
- Artifact/Metadata: MLMD, MinIO/S3.
How Kubeflow Works
Central Dashboard, SDK/CLI, Pipelines UI, Argo Workflows, Katib, TF/PyTorch jobs, Artifact stores, Serving via KServe, monitoring via Prom/Grafana.
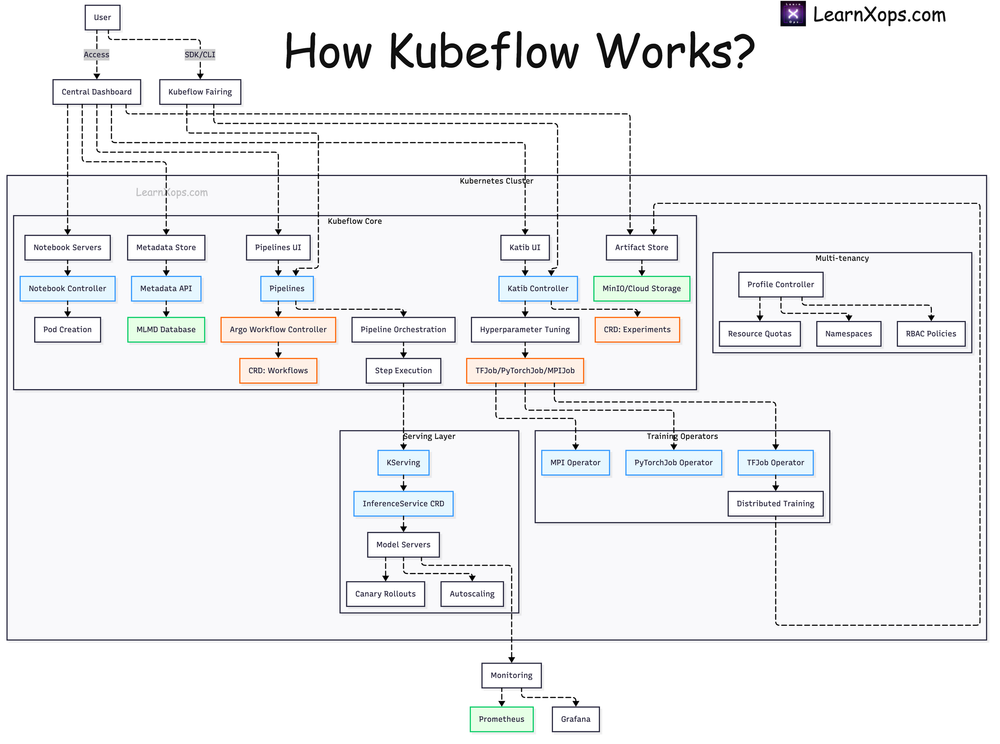
Step vs Component (Airflow vs KFP)
| Feature | Airflow (Step) | KFP (Component) |
|---|---|---|
| Paradigm | Task‑oriented DAGs | Reusable components |
| Unit | Operators/functions | Container components |
| Use Case | ETL/general workflows | ML lifecycle pipelines |
| Definition | Python APIs | Python DSL/YAML |
| Reusability | Low‑moderate | High |
| Isolation | Often shared env | Per‑step container |
| Metadata | Limited/XCom | Artifacts/lineage |
| Kubernetes | Optional | Native |
Install Kubeflow (Local, kind)
- Prereqs: 16GB RAM, 8 CPU, kind 0.27+, kustomize, Docker/Podman.
- For smaller machines, trim example/kustomization.yaml.
Kernel tweaks
sudo sysctl fs.inotify.max_user_instances=2280
sudo sysctl fs.inotify.max_user_watches=1255360
1) Create kind Cluster
cat <<EOF | kind create cluster --name=kubeflow --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
image: kindest/node:v1.32.0@sha256:c48c62eac5da28cdadcf560d1d8616cfa6783b58f0d94cf63ad1bf49600cb027
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
apiServer:
extraArgs:
"service-account-issuer": "https://kubernetes.default.svc"
"service-account-signing-key-file": "/etc/kubernetes/pki/sa.key"
EOF
2) Save kubeconfig
kind get kubeconfig --name kubeflow > /tmp/kubeflow-config
export KUBECONFIG=/tmp/kubeflow-config
3) Image pull secret
docker login
kubectl create secret generic regcred \
--from-file=.dockerconfigjson=$HOME/.docker/config.json \
--type=kubernetes.io/dockerconfigjson
4) Install Kubeflow (kustomize)
git clone https://github.com/kubeflow/manifests.git
cd manifests
while ! kustomize build example | kubectl apply --server-side --force-conflicts -f -; do
echo "Retrying to apply resources";
sleep 20;
done
This applies applications/ and common/ via kustomize.
Verify pods
kubectl get pods -n cert-manager
kubectl get pods -n istio-system
kubectl get pods -n auth
kubectl get pods -n oauth2-proxy
kubectl get pods -n knative-serving
kubectl get pods -n kubeflow
Port‑forward Dashboard
kubectl port-forward svc/istio-ingressgateway -n istio-system 8080:80
Open http://localhost:8080 → Dex login (user@example.com / 12341234).
After login, the Central Dashboard loads.
Simple scikit‑learn Pipeline (KFP)
Requirements: Python 3.7+, KFP SDK, Docker, running Kubeflow.
pip install kfp scikit-learn pandas joblib
from kfp import dsl
from kfp.components import create_component_from_func
# Step 1: Preprocess
def preprocess():
from sklearn.datasets import load_iris
import pandas as pd
import joblib
iris = load_iris(as_frame=True)
df = iris.frame
df.to_csv('/tmp/iris.csv', index=False)
joblib.dump(iris.target_names, '/tmp/target_names.pkl')
print("Data preprocessed")
preprocess_op = create_component_from_func(
preprocess,
base_image='python:3.8-slim',
packages_to_install=['scikit-learn', 'pandas', 'joblib']
)
# Step 2: Train
def train():
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import joblib
df = pd.read_csv('/tmp/iris.csv')
X = df.drop(columns='target')
y = df['target']
model = DecisionTreeClassifier()
model.fit(X, y)
joblib.dump(model, '/tmp/model.pkl')
print("Model trained")
train_op = create_component_from_func(
train,
base_image='python:3.8-slim',
packages_to_install=['scikit-learn', 'pandas', 'joblib']
)
# Step 3: Evaluate
def evaluate():
import pandas as pd
import joblib
from sklearn.metrics import accuracy_score
df = pd.read_csv('/tmp/iris.csv')
X = df.drop(columns='target')
y = df['target']
model = joblib.load('/tmp/model.pkl')
acc = accuracy_score(y, model.predict(X))
print(f"Accuracy: {acc}")
evaluate_op = create_component_from_func(
evaluate,
base_image='python:3.8-slim',
packages_to_install=['scikit-learn', 'pandas', 'joblib']
)
@dsl.pipeline(
name='Scikit-learn Iris Pipeline',
description='A pipeline that trains and evaluates a decision tree on Iris data'
)
def iris_pipeline():
preprocess_task = preprocess_op()
train_task = train_op().after(preprocess_task)
evaluate_task = evaluate_op().after(train_task)
from kfp.compiler import Compiler
Compiler().compile(iris_pipeline, 'iris_pipeline.yaml')
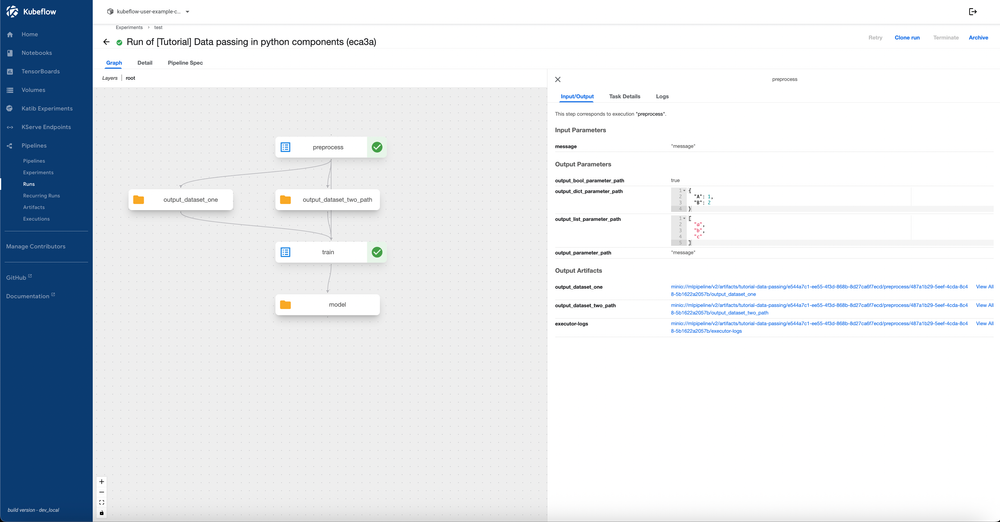
Artifacts Passing (Improved)
from kfp import dsl
from kfp.components import create_component_from_func, InputPath, OutputPath
# Step 1: Preprocess → outputs CSV
def preprocess(output_data_path: OutputPath(str), output_target_names: OutputPath(str)):
from sklearn.datasets import load_iris
import pandas as pd
import joblib
iris = load_iris(as_frame=True)
df = iris.frame
df.to_csv(output_data_path, index=False)
joblib.dump(iris.target_names, output_target_names)
preprocess_op = create_component_from_func(
preprocess,
base_image='python:3.8-slim',
packages_to_install=['scikit-learn', 'pandas', 'joblib']
)
# Step 2: Train → outputs model
def train(input_data_path: InputPath(str), output_model_path: OutputPath(str)):
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import joblib
df = pd.read_csv(input_data_path)
X = df.drop(columns='target')
y = df['target']
model = DecisionTreeClassifier()
model.fit(X, y)
joblib.dump(model, output_model_path)
train_op = create_component_from_func(
train,
base_image='python:3.8-slim',
packages_to_install=['scikit-learn', 'pandas', 'joblib']
)
# Step 3: Evaluate
def evaluate(input_data_path: InputPath(str), input_model_path: InputPath(str)):
import pandas as pd
import joblib
from sklearn.metrics import accuracy_score
df = pd.read_csv(input_data_path)
X = df.drop(columns='target')
y = df['target']
model = joblib.load(input_model_path)
acc = accuracy_score(y, model.predict(X))
print(f"Accuracy: {acc}")
evaluate_op = create_component_from_func(
evaluate,
base_image='python:3.8-slim',
packages_to_install=['scikit-learn', 'pandas', 'joblib']
)
@dsl.pipeline(
name='Scikit-learn Iris Pipeline with Artifacts',
description='Pipeline demonstrating artifact passing'
)
def iris_pipeline():
preprocess_task = preprocess_op()
train_task = train_op(
input_data_path=preprocess_task.outputs['output_data_path']
)
evaluate_task = evaluate_op(
input_data_path=preprocess_task.outputs['output_data_path'],
input_model_path=train_task.outputs['output_model_path']
)
from kfp.compiler import Compiler
Compiler().compile(iris_pipeline, 'iris_pipeline_artifact.yaml')
Challenges
- Build a 3‑step pipeline (prep → train → eval) in KFP.
- Turn each step into a reusable @component or component func.
- Run the pipeline and validate outputs via artifacts/logs.
- Track pipeline status and visualize DAG in UI.
- Add retry/conditional logic using dsl.Retry or dsl.Condition.
- Compile and upload pipeline YAML via UI or SDK.
- Store artifacts (model.pkl) with volumes or MinIO/S3.