30 Days of MLOps Challenge · Day 13
 ML Model Deployment – Batch vs Real-time Inference
ML Model Deployment – Batch vs Real-time Inference
Understanding both batch and real-time inference helps you choose the right serving strategy for latency, scalability, and cost—delivering efficient, reliable user experiences in production.
💡 Hey — It's Aviraj Kawade 👋
📚 Key Learnings
- Understand batch vs real-time (online) inference.
- Pick the right method based on latency, scale, and cost.
- Implement and deploy both patterns in practice.
Inference can be done in two primary ways, each with clear trade‑offs.
- Batch Inference — process large datasets on a schedule or trigger.
- Real-Time (Online) Inference — request/response predictions via an API.
🧠 Learn here
Use the zoom controls to inspect the diagrams.
Batch Inference
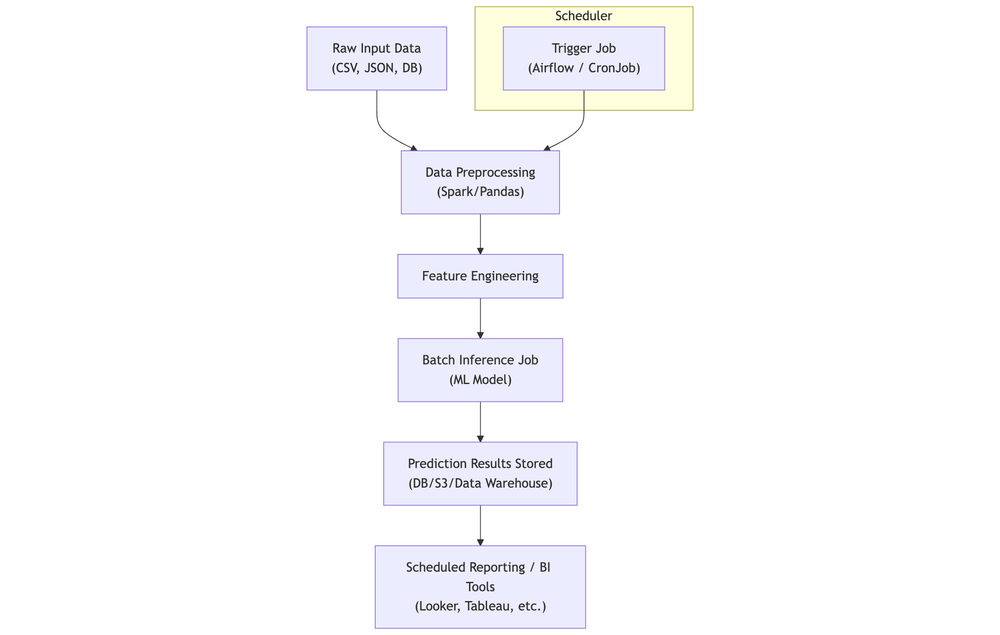
Example Use Cases
- Daily product recommendations
- Bulk risk scoring
- Predictive maintenance reports
Example Flow
- Scheduler triggers job (Airflow, CronJob)
- Preprocess and feature engineer
- Run batch inference at scale
- Store outputs (DB, warehouse, lake)
- Downstream consumption
Real-Time (Online) Inference
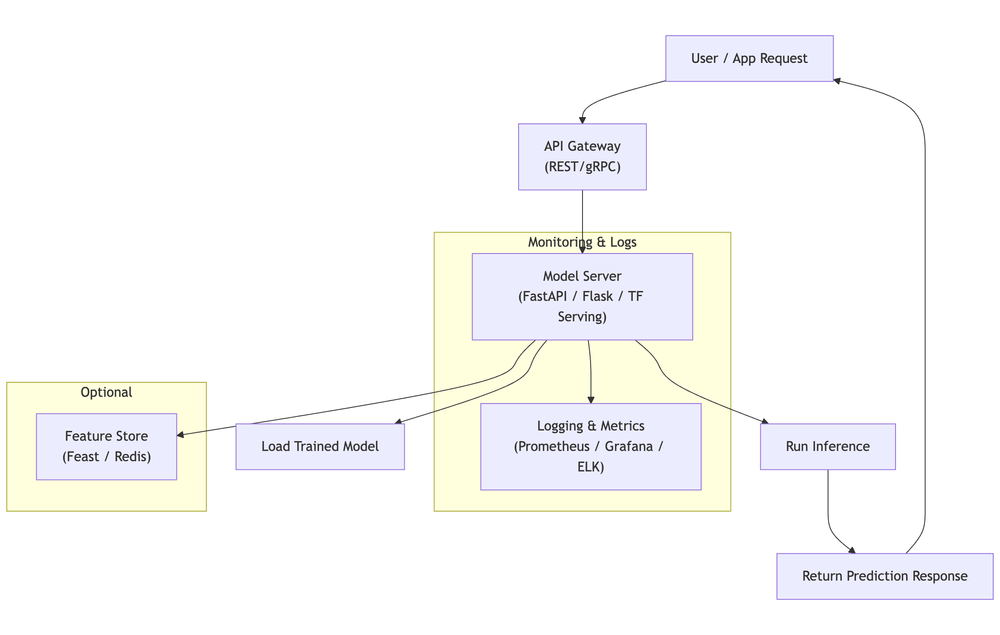
Example Use Cases
- Fraud detection during transactions
- Chatbot and conversational AI
- Recommendations on click
Example Flow
- Request hits API gateway
- Model server processes input (FastAPI, Flask, TF Serving)
- Optional feature store retrieval
- Return prediction within SLA
- Monitor latency, errors, throughput
Comparison: Batch vs Real-Time
| Feature | Batch | Real-Time |
|---|---|---|
| Latency | High (minutes to hours) | Low (ms to seconds) |
| Data Volume | Large datasets | Single/small records |
| Infrastructure | Data pipelines, batch jobs (Airflow) | Web APIs, model servers (FastAPI, TF Serving) |
| Trigger | Scheduled (cron, DAG) | On‑demand (request/event) |
| Cost | Efficient for large volume | Higher for low latency |
| Deployment | Offline/internal processes | Exposed API endpoint |
| Feedback loop | Slower | Fast/immediate |
| Common tools | Spark, Pandas, Airflow | FastAPI, Seldon, Triton |
Tools & Frameworks
| Purpose | Batch Inference | Real-Time Inference |
|---|---|---|
| Frameworks | Apache Spark, Dask, Pandas | FastAPI, Flask, gRPC, TF Serving |
| Orchestration | Airflow, KFP | KServe, Seldon, BentoML |
| Deployment | Kubernetes CronJobs | Kubernetes Deployment + Service |
Choosing the Right Method
Use Case
- Real‑time user interaction → Online inference
- Analytics & reporting → Batch inference
- Stream processing → Hybrid/near real‑time
Latency Requirements
| Latency | Recommended |
|---|---|
| < 1 second | Real‑time (Online) |
| 1 sec – few minutes | Near real‑time / Micro‑batch |
| Minutes – hours | Batch |
Scalability
| Traffic Pattern | Serving Method |
|---|---|
| High, bursty | Real‑time + autoscaling |
| Periodic jobs | Batch pipelines |
| Mixed | Hybrid (Batch + Real‑time) |
Decision Matrix
| Use Case | Latency | Traffic | Recommended |
|---|---|---|---|
| Product Recommendation on Click | < 1s | High | Real‑time |
| Daily Risk Score Calculation | Hours | Low | Batch |
| Fraud Detection During Payment | < 500ms | Very High | Real‑time |
| IoT Sensor Stream Classification | ~1s | High, Continuous | Near Real‑time / Hybrid |
| Email Campaign Personalization | Minutes | Low | Batch |
Quick Examples
| Scenario | Recommended Type |
|---|---|
| Daily/weekly reports | Batch |
| Prediction affects immediate UX | Real‑time |
| Limited real‑time infra | Batch |
| Prevent fraud instantly | Real‑time |
Hands-on Demo: Structure
ml-inference-demo/
├── batch_inference/
│ ├── preprocess.py
│ ├── inference.py
│ ├── run_batch_job.py
│ └── airflow_dag.py
├── realtime_inference/
│ ├── main.py
│ ├── model.pkl
│ └── Dockerfile
├── models/
│ └── train_model.ipynb
├── data/
│ └── sample_input.csv
└── README.md
Batch Scripts
# batch_inference/preprocess.py
import pandas as pd
def preprocess(input_path, output_path):
df = pd.read_csv(input_path)
df.fillna(0, inplace=True)
df.to_csv(output_path, index=False)
# batch_inference/inference.py
import pandas as pd
import joblib
def run_inference(input_path, model_path, output_path):
df = pd.read_csv(input_path)
model = joblib.load(model_path)
predictions = model.predict(df)
pd.DataFrame({'prediction': predictions}).to_csv(output_path, index=False)
# batch_inference/run_batch_job.py
from preprocess import preprocess
from inference import run_inference
preprocess('data/sample_input.csv', 'data/cleaned.csv')
run_inference('data/cleaned.csv', 'models/model.pkl', 'data/output.csv')
# batch_inference/airflow_dag.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
from inference import run_inference
def batch_job():
run_inference('data/cleaned.csv', 'models/model.pkl', 'data/output.csv')
dag = DAG('batch_inference', start_date=datetime(2024, 1, 1), schedule_interval='@daily')
PythonOperator(task_id='run_batch', python_callable=batch_job, dag=dag)
Real-Time API
# realtime_inference/main.py
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
app = FastAPI()
model = joblib.load("model.pkl")
class InputData(BaseModel):
features: list
@app.post("/predict")
def predict(data: InputData):
prediction = model.predict([data.features])
return {"prediction": float(prediction[0])}
# realtime_inference/Dockerfile
FROM python:3.10-slim
WORKDIR /app
COPY . .
RUN pip install --no-cache-dir fastapi uvicorn joblib pydantic scikit-learn
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
# models/train_model.ipynb (Python cells)
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import joblib
data = pd.read_csv('../data/sample_input.csv')
X = data.drop('target', axis=1)
y = data['target']
model = RandomForestClassifier()
model.fit(X, y)
joblib.dump(model, '../realtime_inference/model.pkl')
# data/sample_input.csv
feature1,feature2,feature3,target
1.0,2.5,3.0,0
2.1,0.3,3.3,1
1.2,1.8,2.2,0
Deployment Options
| Layer | Batch Inference | Real-Time Inference |
|---|---|---|
| Scheduler | Airflow, CronJob | N/A |
| Serving | Offline scripts | FastAPI + Uvicorn |
| Containerization | Docker (optional) | Docker |
| Orchestration | K8s Job / CronJob | K8s Deployment + Service |
| Storage | S3, DW, DB | Redis/NoSQL/In‑memory (optional) |
| Monitoring | Airflow UI | Prometheus + Grafana |
Monitoring & Logging
Batch
- Track DAG success/failure in Airflow
- Persist logs (e.g., S3, logging service)
Real‑Time
- Monitor latency, throughput, error rates (Prometheus)
- Set alerts for p95/p99, 5xx rates
Common Pitfalls
- Batch: Missing schema validation; brittle DAG error handling.
- Real‑Time: Re‑loading model per request; underutilizing micro‑batching when acceptable.
🔥 Challenges
- List ML tasks from prior days and categorize into batch vs real‑time.
- Read AWS SageMaker Batch Transform vs Real‑Time Endpoints and write a short gist.
- Prepare a dummy dataset (CSV/JSON) for batch processing.
- Reuse your model from Day 11 or Day 12 and deploy both patterns.