30 Days of MLOps Challenge · Day 12
 CI/CD for ML with GitHub Actions – Automate Test-Train-Deploy Pipelines
CI/CD for ML with GitHub Actions – Automate Test-Train-Deploy Pipelines
Automate testing, training, packaging, and deployment with GitHub Actions. Bring reproducibility and speed to your ML lifecycle.
💡 Hey — It's Aviraj Kawade 👋
Key Learnings
- Why CI/CD is important in ML workflows.
- Automate testing, training, packaging, and deployment.
- Write and configure GitHub Actions workflows.
- Use triggers (push, PR, manual) and job matrices.
- Leverage caching, env vars, and secrets.
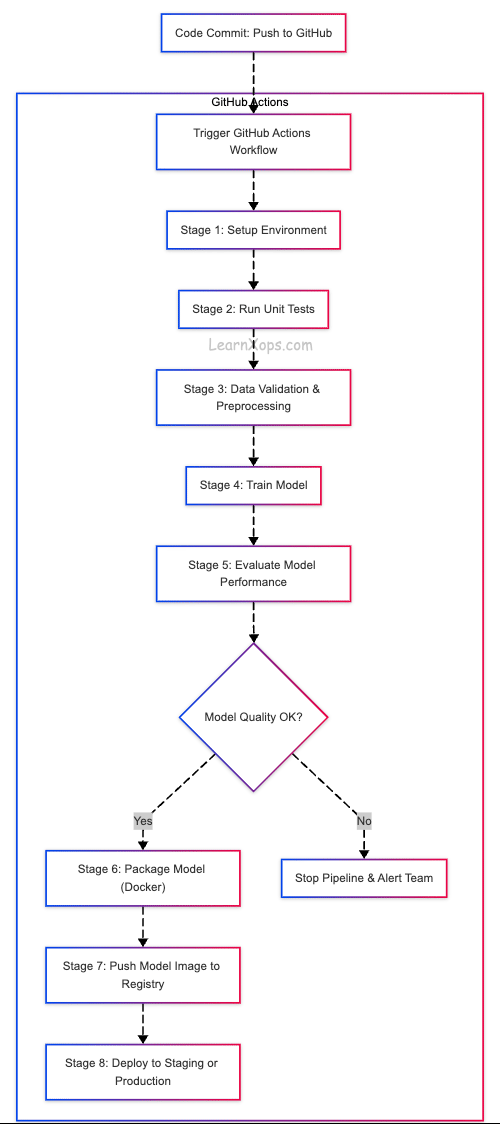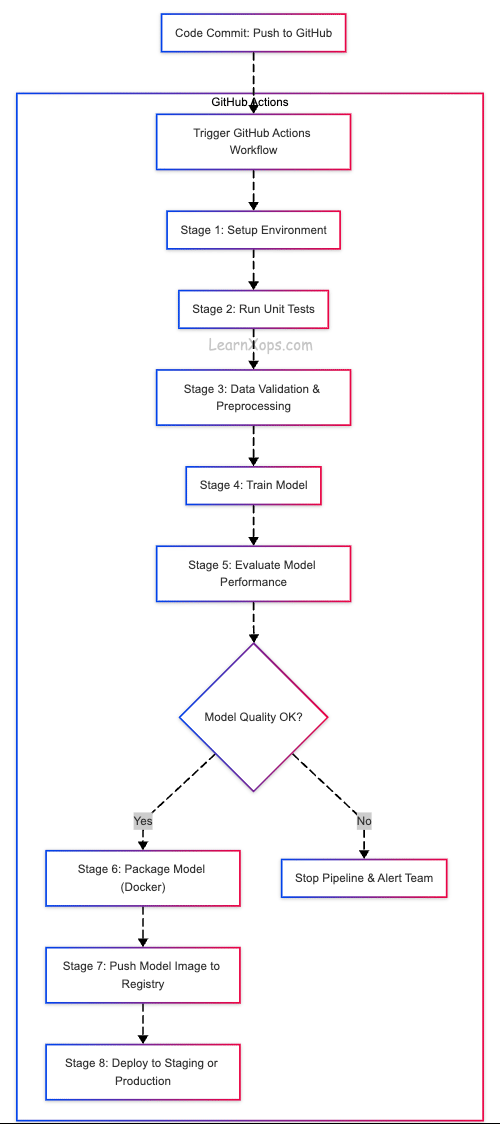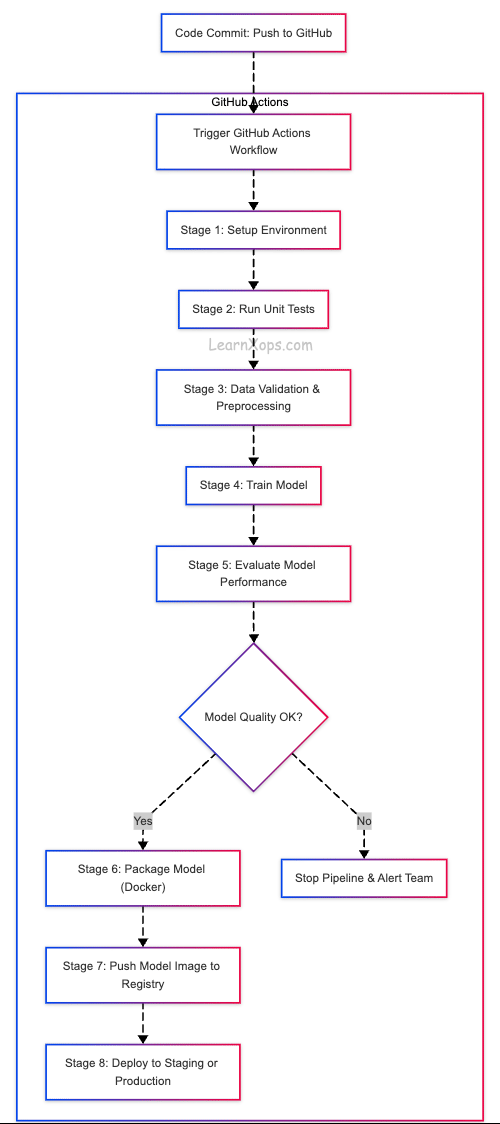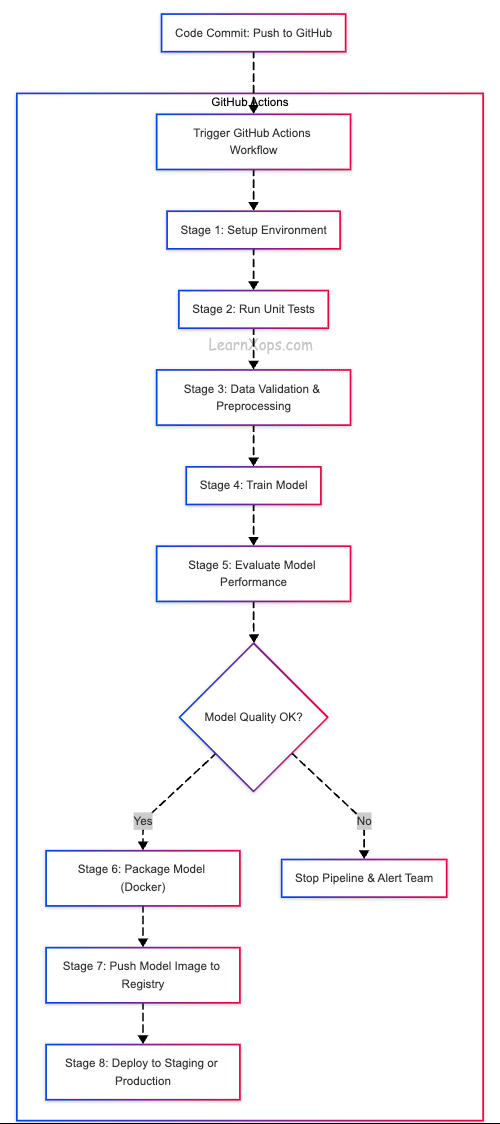

Why CI/CD Matters for ML
- Mitigate data and code drift via automated tests and retraining.
- Ensure reproducibility with versioned envs and tracked lineage.
- Automate train/eval/deploy and hook in monitoring.
- Improve collaboration and iteration velocity.
Automating ML Workflows
Automated Testing
# tests/test_preprocessing.py
import pytest
from preprocessing import clean_text
def test_clean_text():
assert clean_text("Hello, WORLD!!!") == "hello world"
Model Training Automation
# train.py
import argparse
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
parser = argparse.ArgumentParser()
parser.add_argument('--max_iter', type=int, default=100)
args = parser.parse_args()
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = LogisticRegression(max_iter=args.max_iter)
model.fit(X_train, y_train)
print(f"Accuracy: {model.score(X_test, y_test):.2f}")
Packaging & Deployment
# Dockerfile
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt ./
RUN pip install -r requirements.txt
COPY . .
CMD ["python", "serve.py"]
Example GitHub Actions
name: ML Workflow Automation
on:
push:
branches: [main]
jobs:
build-train-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: Install Dependencies
run: pip install -r requirements.txt
- name: Run Tests
run: pytest tests/
- name: Train Model
run: python train.py --max_iter 200
- name: Build Docker Image
run: docker build -t ml-model:latest .
- name: Push Docker Image
run: |
echo ${{ secrets.DOCKER_PASSWORD }} | docker login -u ${{ secrets.DOCKER_USERNAME }} --password-stdin
docker tag ml-model:latest myrepo/ml-model:latest
docker push myrepo/ml-model:latest
- name: Deploy to Kubernetes
run: kubectl apply -f k8s/deployment.yaml
Triggers & Advanced
on:
push:
branches: [main]
paths:
- 'src/**'
- 'data/**'
pull_request:
branches: [main]
workflow_dispatch:
inputs:
retrain:
description: 'Trigger retraining'
required: false
default: 'false'
jobs:
train-model:
if: github.event_name == 'workflow_dispatch' && github.event.inputs.retrain == 'true'
runs-on: ubuntu-latest
strategy:
matrix:
python-version: [3.8, 3.9, 3.10]
model: [xgboost, randomforest]
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4
with:
python-version: ${{ matrix.python-version }}
- uses: actions/cache@v3
with:
path: ~/.cache/pip
key: ${{ runner.os }}-pip-${{ hashFiles('**/requirements.txt') }}
- run: pip install -r requirements.txt
- run: python train.py --model ${{ matrix.model }}
Challenges
- Create a workflow that runs pytest on push/PR.
- Automate your train.py in the workflow.
- Cache dependencies using actions/cache.
- Build and push a Docker image after training.
- Use GitHub Secrets to upload model to S3.
- Save trained model as a GitHub artifact or release.
- Split training & deployment into separate jobs with needs.
- Organize repo for production ML workflows.