30 Days of MLOps Challenge · Day 14
 Data Drift & ML Model Drift Detection – Keep Your Models Relevant
Data Drift & ML Model Drift Detection – Keep Your Models Relevant
Learn to detect and address data and model drift so your deployed models stay accurate and reliable as real‑world data evolves.
💡 Hey — It's Aviraj Kawade 👋
📚 Key Learnings
- Data drift vs model (concept) drift
- Business risks of ignoring drift
- Detection techniques and where drift fits in MLOps
🧠 Learn here
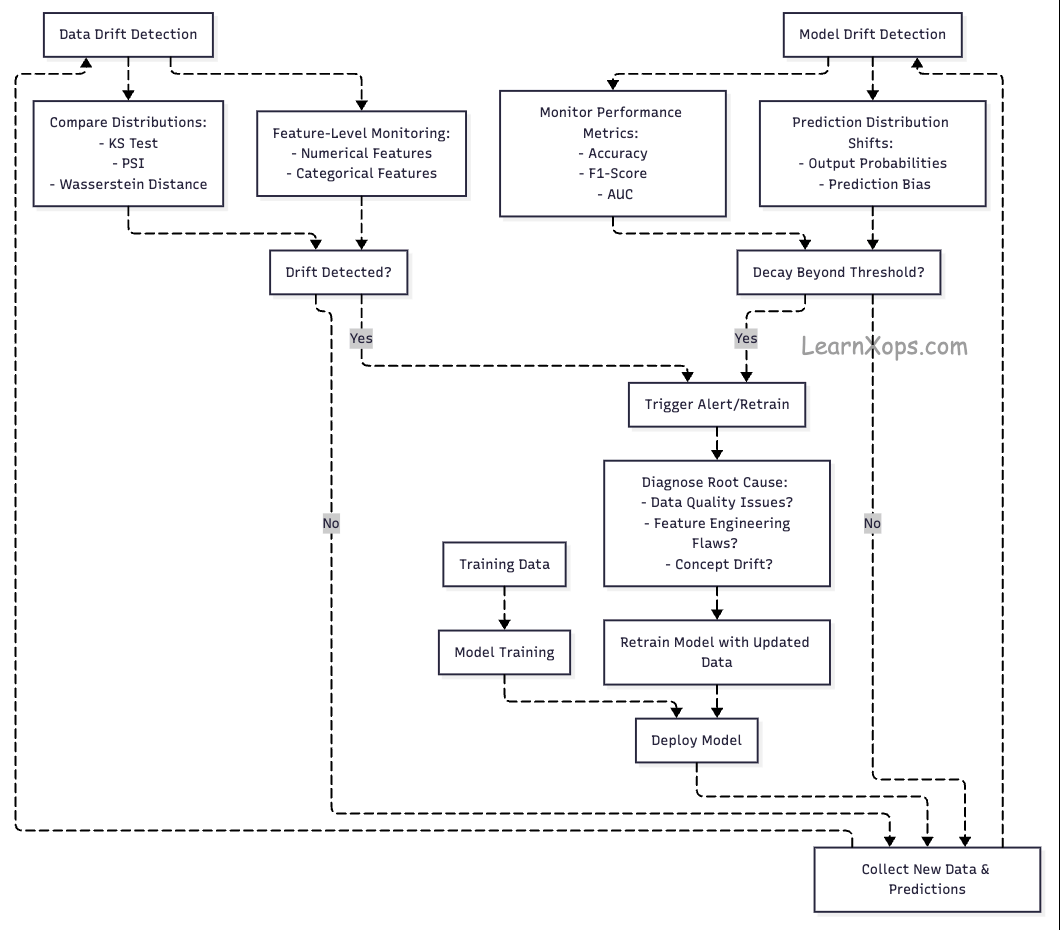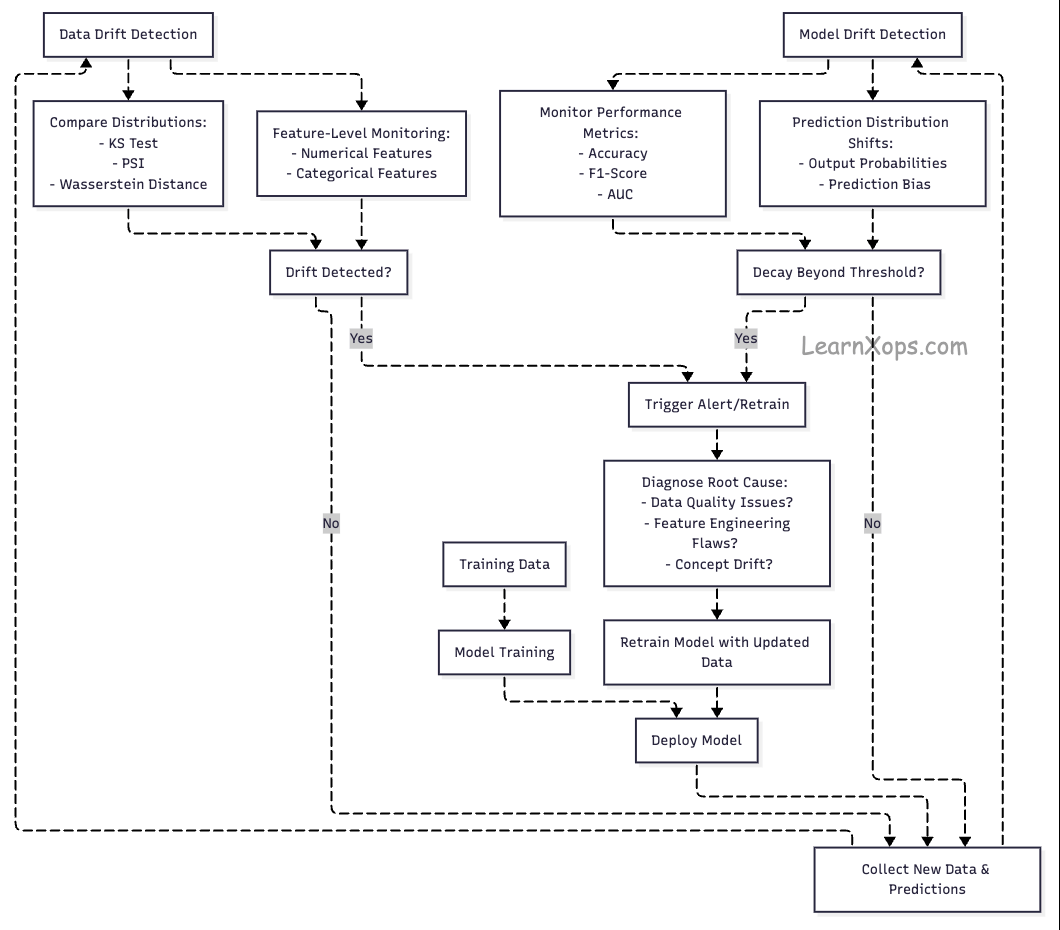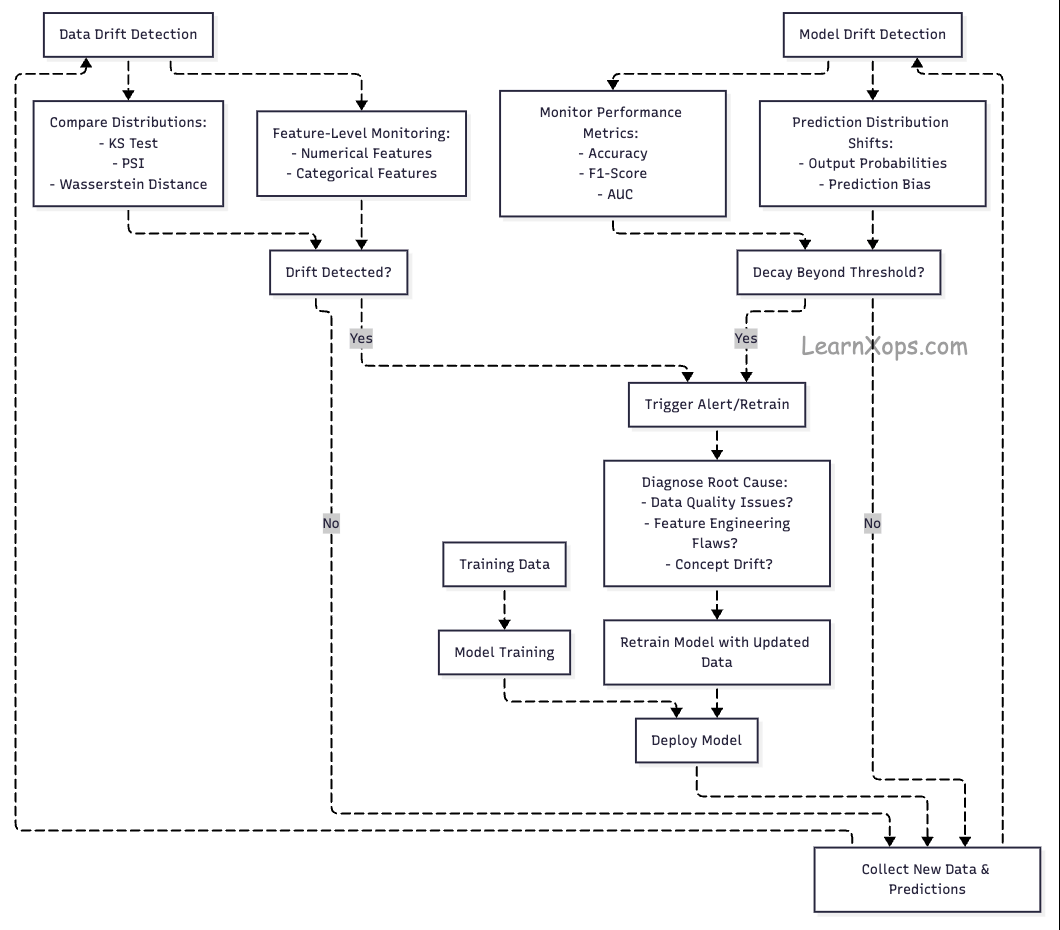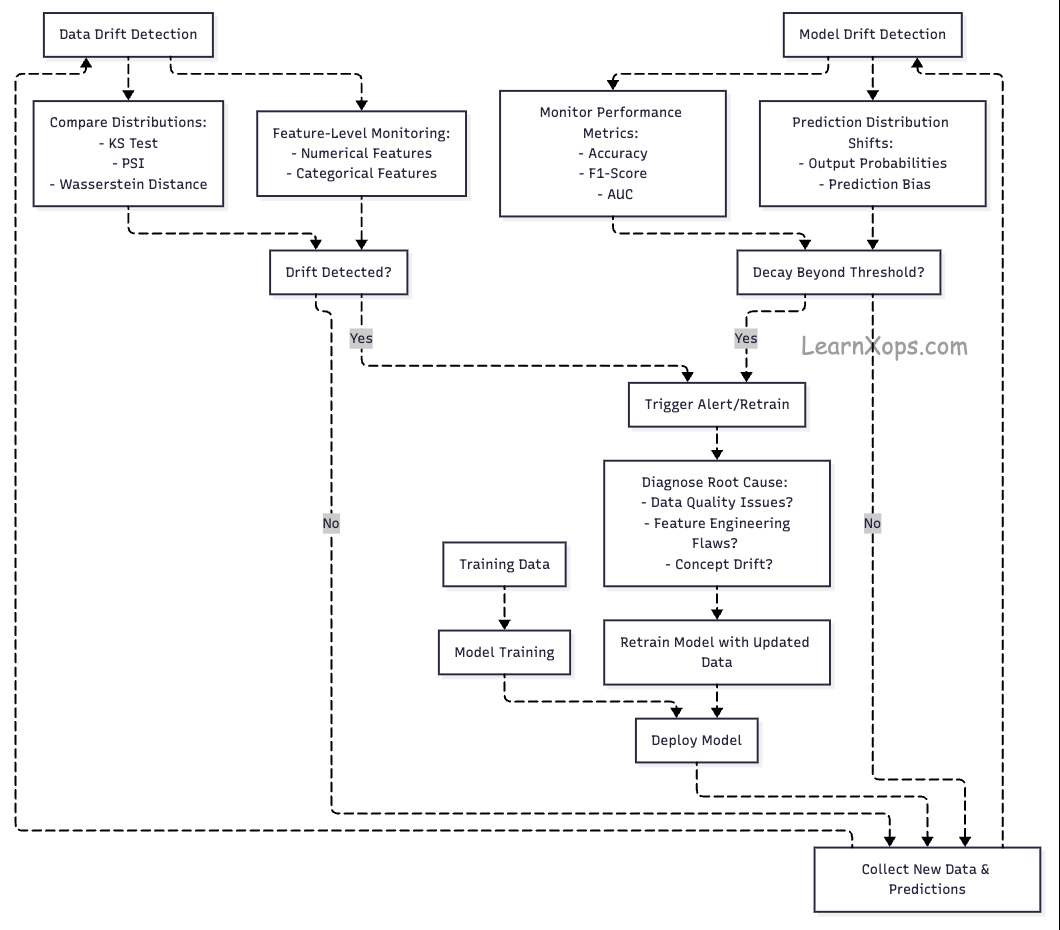
What is Drift in ML?
Drift is change over time that harms model performance.
- Data Drift: Input distributions shift vs training data.
- Model (Concept) Drift: Relationship between features and labels changes.
Data Drift
Causes: seasonality, behavior shifts, sensor recalibration, new demographics.
Detect: KS test, divergence metrics, distribution plots.
Model Drift
Causes: evolving patterns (e.g., fraud tactics), label drift, target shift.
Detect: continuous performance monitoring, A/B tests, shadow deploys.
Business Risks
- Bad predictions, degraded accuracy, loss of trust.
- Customer dissatisfaction and churn.
- Revenue loss and wasted resources.
- Compliance and legal risks.
- Operational inefficiencies and growing technical debt.
Techniques & Tools
EvidentlyAI
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
report = Report(metrics=[DataDriftPreset()])
report.run(reference_data=train_df, current_data=test_df)
report.show()
WhyLabs + WhyLogs
import whylogs as why
from whylogs.api.writer.whylabs import WhyLabsWriter
profile = why.log(pandas=df).profile()
writer = WhyLabsWriter(org_id="org-id", api_key="your-key")
writer.write(file=profile.view())
Alibi Detect
from alibi_detect.cd import KSDrift
cd = KSDrift(x_ref=X_train, p_val=0.05)
preds = cd.predict(X_test)
print(preds)
Arize AI
from arize.pandas.logger import Client
client = Client(space_key="", api_key="")
client.log_dataframe(df)
Pro Tips
- Establish baselines from training data.
- Monitor both inputs and predictions.
- Define thresholds and automate alerts.
- Hook retraining via CI/CD when drift crosses limits.
Where It Fits
- Train & Evaluate
- Deploy
- Monitor & Detect Drift
- Retrain / Update
Integration Points
Batch jobs: Periodic analysis vs training baselines; generate reports.
Real‑time: Stream monitoring; trigger alerts on threshold breach.
Alerts & Dashboards
Thresholds
- Set boundaries for accuracy, precision, recall, etc.
- Define statistical limits for feature and prediction drift.
Automated Alerting
- Use Prometheus/Grafana or Evidently alerts.
- Integrate with PagerDuty, Slack.
Dashboards
- Visualize drift over time vs baseline.
- Show alert history and retraining recommendations.
🔥 Challenges
- Data Drift: Use Evidently to compare reference.csv vs current.csv; highlight changed features; tune thresholds.
- Model Drift: Simulate accuracy drop with a new test set; analyze precision/recall/F1; decide on retraining.
- Automation: Integrate Evidently in a notebook/pipeline; schedule daily checks; alert via email/Slack; store reports.