30 Days of MLOps Challenge · Day 15
 Automated Retraining ML Pipelines – Keep Your ML Models Fresh
Automated Retraining ML Pipelines – Keep Your ML Models Fresh
Automate retraining so models stay accurate as data evolves. Build scalable, production‑grade pipelines that update stale models with minimal human intervention.
💡 Hey — It's Aviraj Kawade 👋
📚 Key Learnings
- Know the triggers for retraining (drift, performance, time, new data, business change).
- Design automated pipelines with version control and registries.
- Validate data/features before retraining; promote only better models.
🧠 Learn here
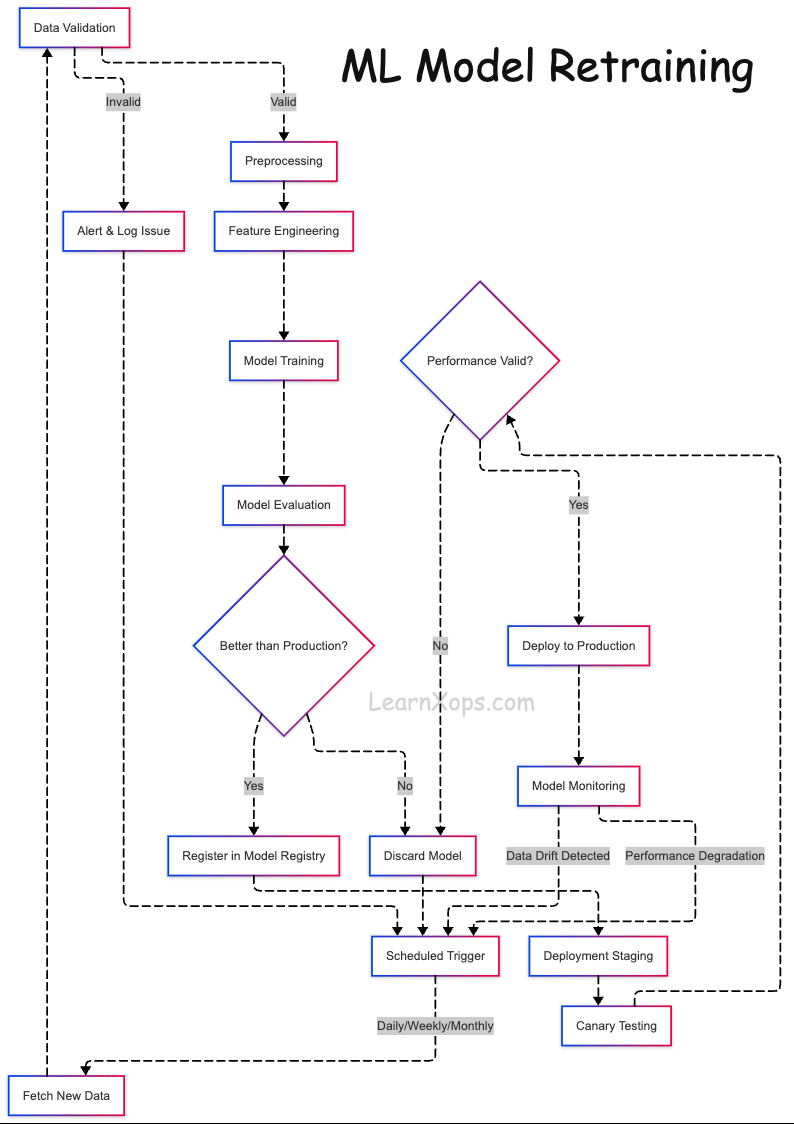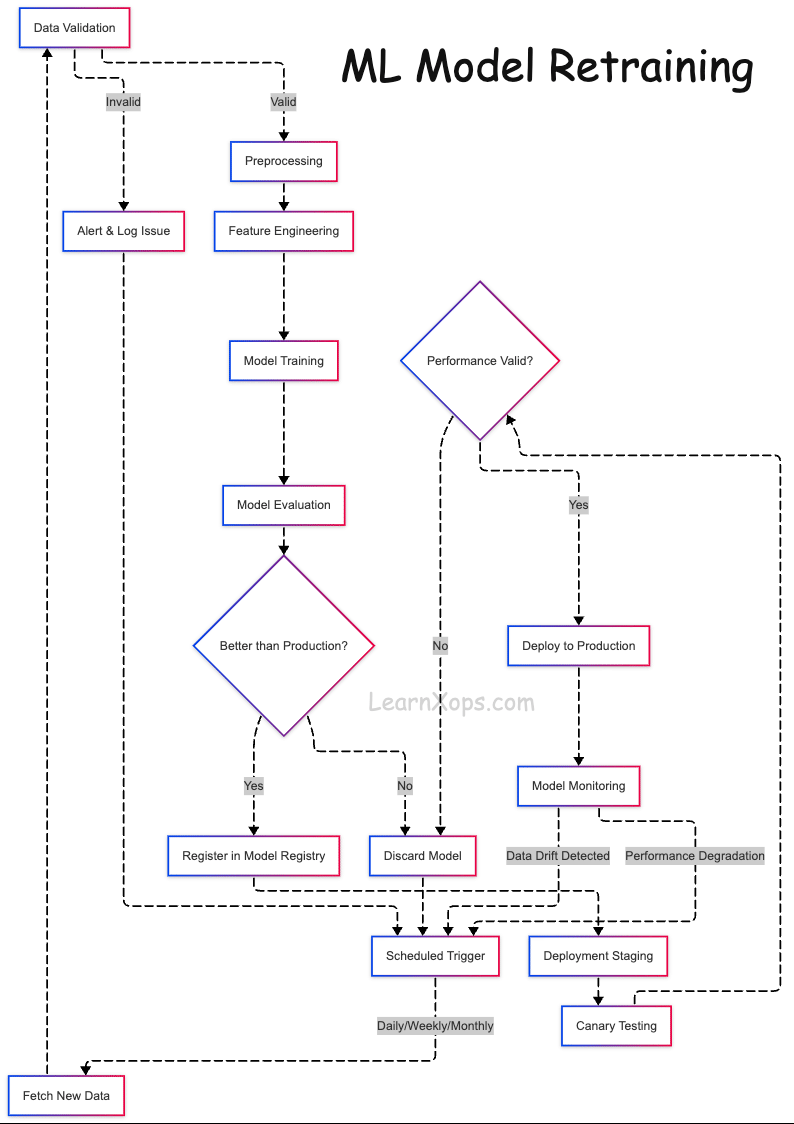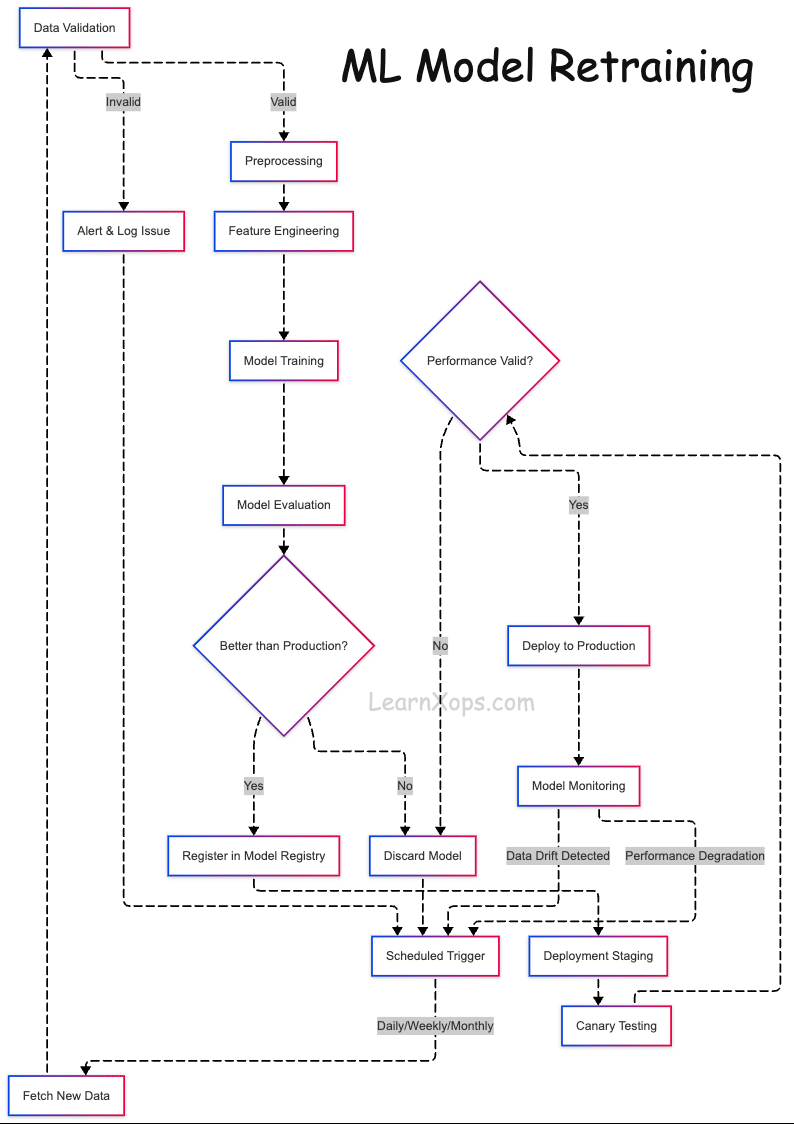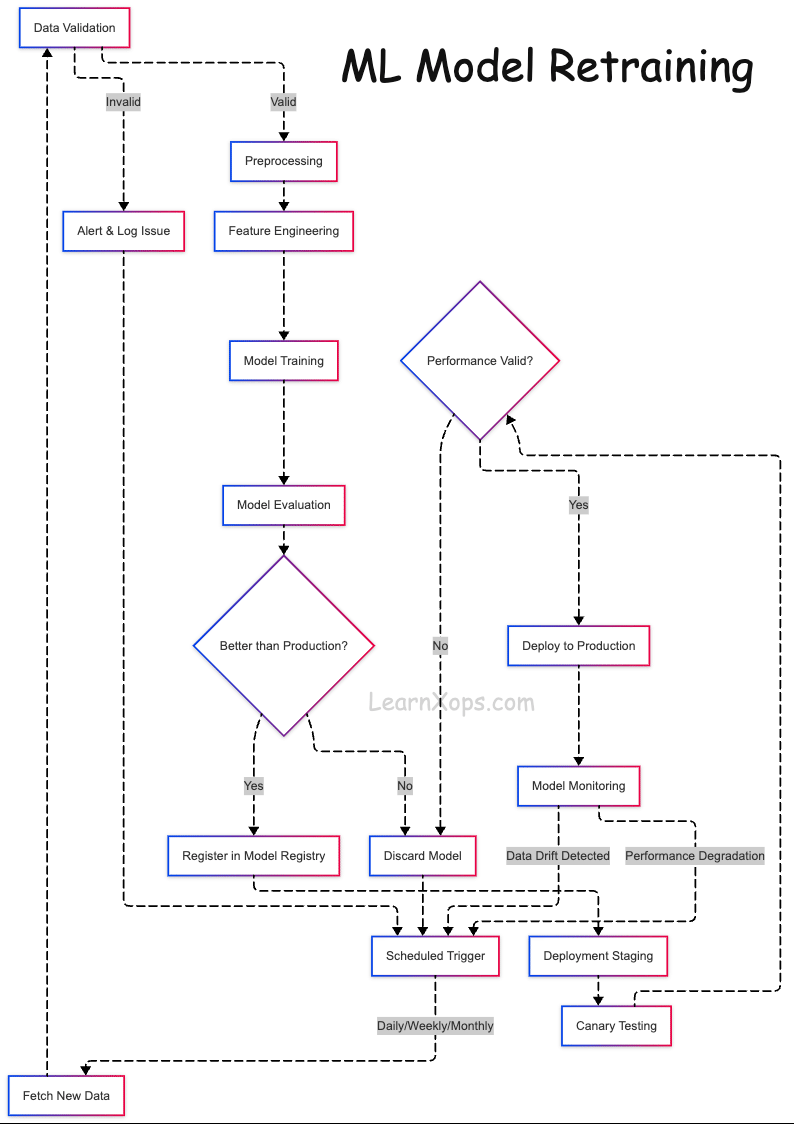
What is ML Model Retraining?
Updating a model with new/additional data to maintain or improve performance over time (e.g., weekly recommendations reflecting seasonal trends and new products).
Why Retraining?
- Maintain accuracy as data patterns change
- Stay relevant to current distributions
- Adapt to new behaviors and use cases
Common Triggers
- Performance Drop: Metric decline vs baseline (e.g., accuracy < 85%).
- Data Drift: Input distribution shifts (EvidentlyAI, WhyLabs, Alibi Detect).
- Model Drift: Prediction behavior shifts (Alibi Detect, Arize AI).
- Time‑Based: Periodic schedule (e.g., weekly).
- New Data: Significant fresh labeled data.
- Business Change: New objectives/constraints.
What Happens During Retraining?
- Collect new data (features + labels)
- Preprocess and feature engineer (consistent with training)
- Retrain model (reuse/tune architecture)
- Evaluate & compare to production baseline
- Deploy if it outperforms; rollback otherwise
Automation Tools
| Tool | Purpose |
|---|---|
| Airflow / Kubeflow Pipelines | Workflow orchestration |
| DVC / LakeFS | Data versioning |
| MLflow | Experiment tracking & registry |
| GitHub Actions | CI/CD automation |
| Docker + Kubernetes | Reproducible env & scaling |
Automated Pipelines with Version Control
- Data Ingestion: Batch/stream sources (Airflow, Kafka, Glue). Version inputs (DVC, LakeFS, Delta).
- Data Validation: Great Expectations, TFDV for schema/quality checks.
- Training: Containerized (Docker), scheduled or event‑based; track with MLflow/W&B.
- Evaluation: Compare vs prod model on same validation set; use Evidently or custom scripts.
- Model Registry: Register versions (MLflow/SageMaker); tag candidate/staging/prod; auto‑approve when better.
- Deployment: Promote and deploy (Seldon, KServe, FastAPI) with monitoring (Prometheus/Grafana, Alibi).
Orchestration Choices
| Feature / Tool | Airflow | Kubeflow Pipelines | CI/CD Workflows |
|---|---|---|---|
| Purpose | General DAGs/ETL | ML on Kubernetes | Automate build/test/deploy |
| Env | Python server | Kubernetes‑native | Runners/containers |
| Definition | Python DAGs | Python+YAML/DSL | YAML declarative |
| Versioning | Via Git | Built‑in components/experiments | Git + artifacts |
| Retries/Failures | Built‑in | Built‑in | Conditions/retries |
Feature & Data Validation
- Schema checks: columns/types present; mandatory fields
- Nulls and ranges: thresholds for missing/invalid values
- Statistical drift and outliers (Evidently, WhyLabs, Alibi, PyOD)
- Category/value domains; target balance
| Tool | Use Case |
|---|---|
| Great Expectations | Data pipeline validation |
| Pandera | Pandas schema checks |
| EvidentlyAI | Drift detection & reports |
| WhyLabs | Logging/validation realtime |
| Alibi Detect | Drift & outlier detection |
Model Registry Updates
Registries track versions, metadata, stages, and enable governance and rollback.
import mlflow
import mlflow.sklearn
with mlflow.start_run():
mlflow.sklearn.log_model(model, "model")
mlflow.log_metrics({"accuracy": 0.91})
mlflow.set_tag("dataset_version", "v3.2")
result = mlflow.register_model(
"runs:/<run_id>/model", "ChurnPredictionModel"
)
client = mlflow.tracking.MlflowClient()
client.transition_model_version_stage(
name="ChurnPredictionModel",
version=result.version,
stage="Staging"
)
- Register new version with artifacts/metrics/code hash.
- Promote from Staging → Production after tests.
- Notify stakeholders; trigger deployment pipelines.
🔥 Challenges
- Load latest dataset; compare vs reference for drift; retrain if significant.
- Add evaluation vs previous model; save/version the new one.
- Schedule daily/weekly via Airflow or CI; send Slack/email alerts when retraining triggers.
- Integrate registry (tag versions); containerize; push to S3 or GitHub Releases.
- Document runs with timestamp, accuracy, data range; loop into Day 12 CI/CD.