 MLOps Tools Landscape – Explore the Ecosystem
MLOps Tools Landscape – Explore the Ecosystem
Understand the tools that power end‑to‑end ML workflows—from data versioning to orchestration, deployment, and monitoring.
Diagram: Tools Landscape
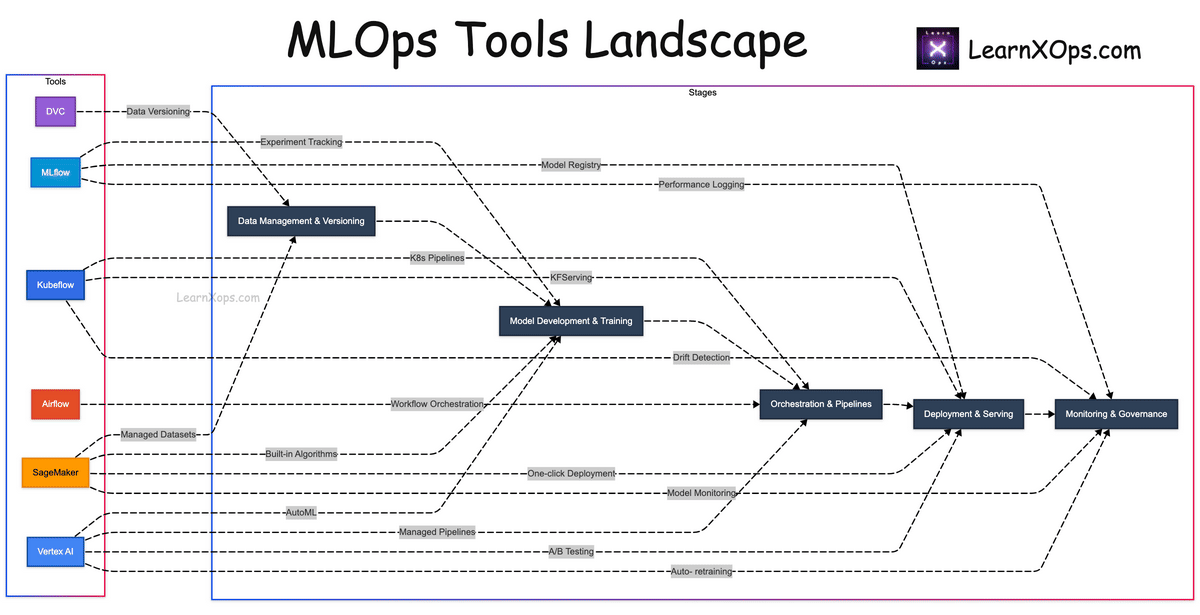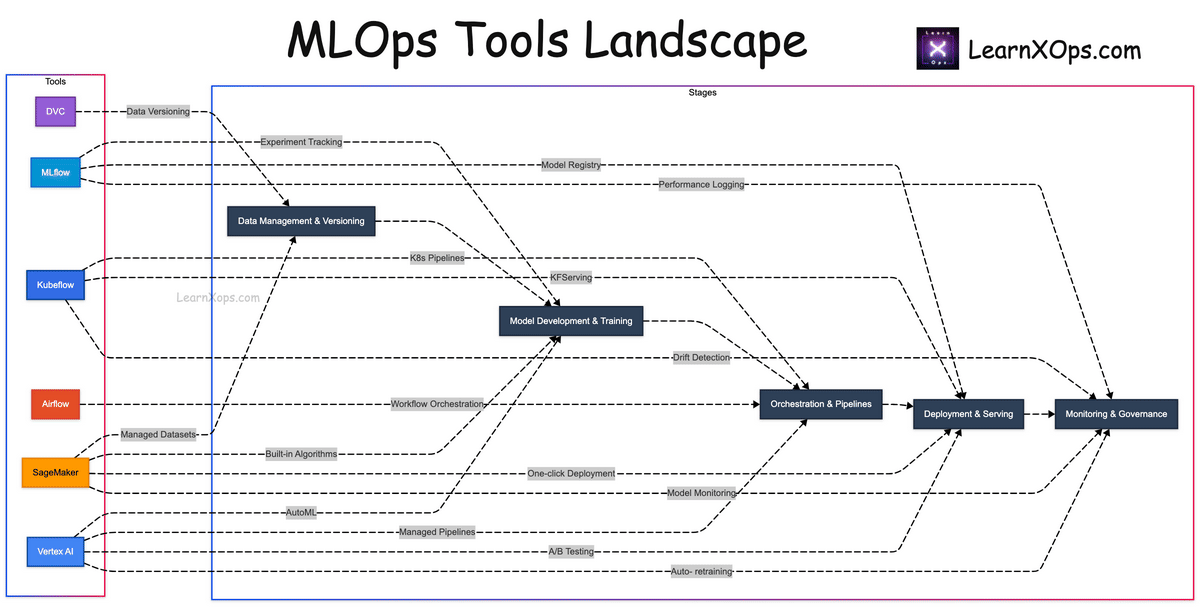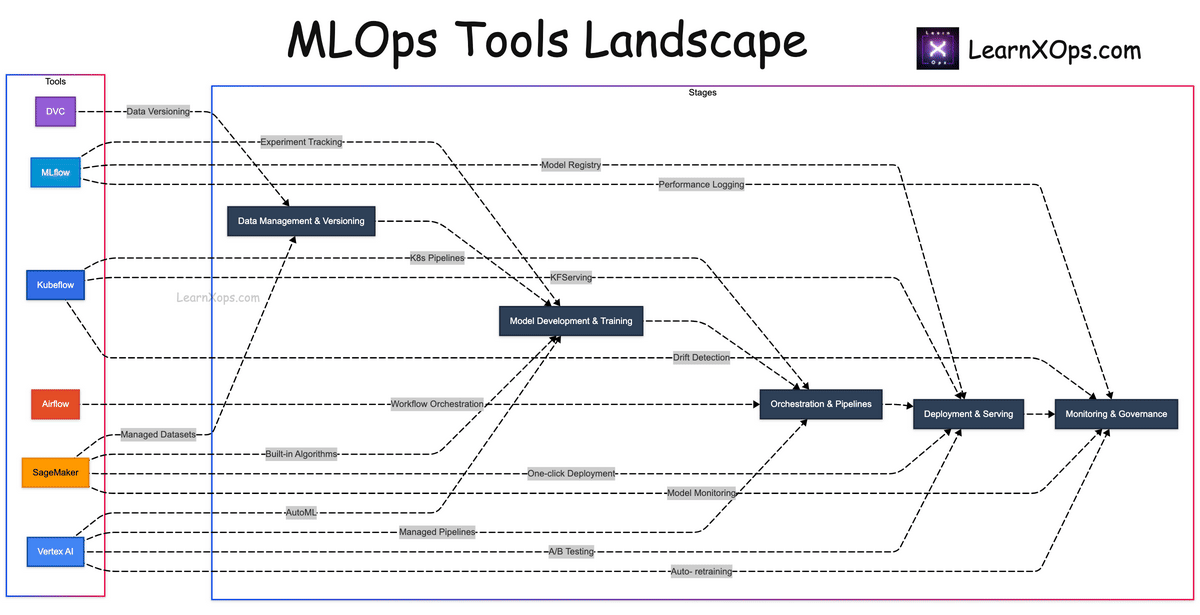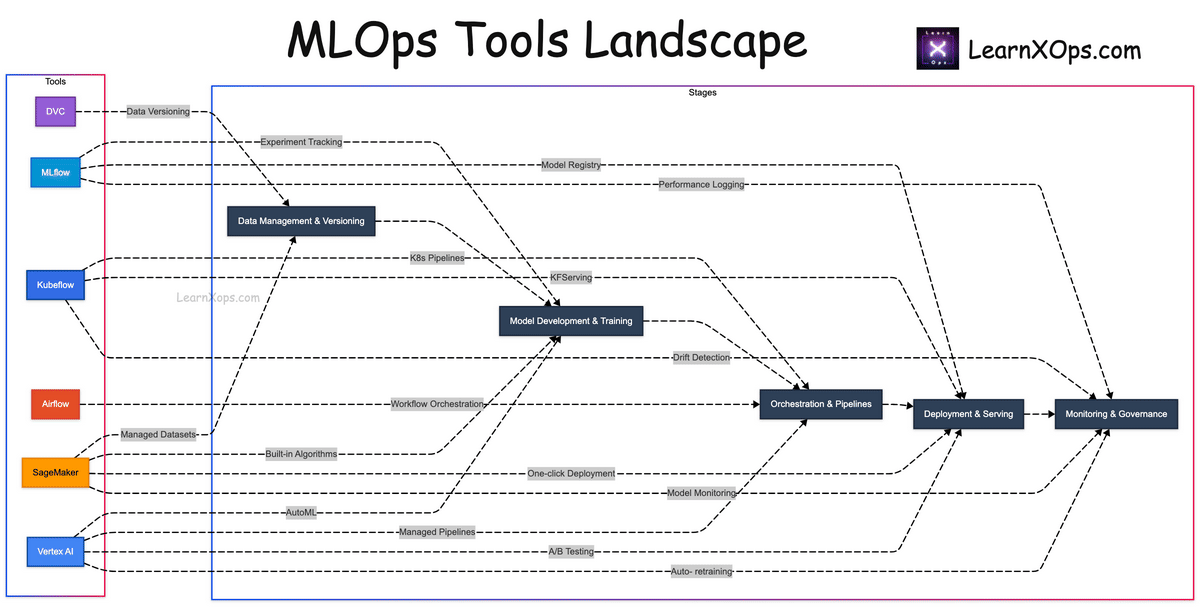
Tip: Use + / − or Ctrl + Mouse Wheel to zoom. Scroll to pan.
Key Learnings
- Categories of tools across the ML lifecycle.
- Open‑source vs managed services: trade‑offs and when to use each.
- Where tools fit: versioning, training, orchestration, deployment, monitoring.
- Deep dive into MLflow, DVC, Kubeflow, Airflow, SageMaker, and Vertex AI.
Categories of Tools Across the ML Lifecycle
- Data Engineering & Preparation
Collecting, cleaning, transforming, and storing data.
- Data Collection: Apache Nifi, Kafka, Web Scrapers, APIs
- Data Cleaning: OpenRefine, Pandas, DataWrangler
- Data Transformation: Spark, dbt, Airbyte
- Data Storage: PostgreSQL, S3, Delta Lake, BigQuery
- Experimentation & Development
Writing ML code, tracking experiments, and versioning datasets.
- Notebooks & IDEs: Jupyter, Colab, VS Code
- Experiment Tracking: MLflow, Weights & Biases, Neptune.ai
- Data Versioning: DVC, LakeFS
- Feature Stores: Feast, Tecton
- Model Training & Optimization
Training models, tuning hyperparameters, and managing compute.
- Frameworks: TensorFlow, PyTorch, Scikit‑learn, XGBoost
- HPO: Optuna, Ray Tune, Hyperopt
- Distributed Training: Horovod, SageMaker, Vertex AI
- Model Packaging & Deployment
Containerizing models and deploying them as APIs or batch jobs.
- Packaging: ONNX, TorchScript, BentoML
- Deployment: KServe, Seldon Core, SageMaker, Vertex AI
- Containerization: Docker, Podman
- CI/CD: Jenkins, GitHub Actions, GitLab CI
- Model Monitoring & Observability
Tracking performance, drift, and logs in production.
- Monitoring: Prometheus, Grafana, Evidently AI
- Drift Detection: WhyLabs, Fiddler, Arize
- Logging & Tracing: ELK Stack, Jaeger, OpenTelemetry
- Governance & Compliance
Explainability, fairness, and secure access.
- Explainability: SHAP, LIME
- Fairness: AI Fairness 360, Fairlearn
- Security & Access: Vault, OPA, IAM
- Workflow Orchestration
Pipeline orchestration and task scheduling.
- Engines: Apache Airflow, Kubeflow Pipelines, Prefect, Dagster
Open‑Source vs Managed Services
| Feature/Aspect | Open‑Source (MLflow, DVC, Kubeflow) | Managed (SageMaker, Vertex, Azure ML) |
|---|---|---|
| Ease of Setup | Manual install and config | Out‑of‑the‑box minimal config |
| Customization | Highly customizable and flexible | Limited by provider implementation |
| Scalability | Manual scaling on your infra | Auto‑scaled by provider |
| Integration | Broad, may need glue code | Native within ecosystem |
| Cost | Low upfront; infra cost grows | Pay‑as‑you‑go; can be expensive |
| Data Security | Full control of data policies | Provider compliance/standards |
| Maintenance | Manual upgrades and monitoring | Handled by provider |
| Learning Curve | Steeper; infra + tools | Easier; infra abstracted |
| Support | Large OSS communities | Official vendor support |
| Vendor Lock‑In | No lock‑in; portable | Higher lock‑in risk |
Summary: Open‑source suits teams needing flexibility and control. Managed services fit teams optimizing for speed and low ops overhead.
MLOps Tools by Stage
1. Versioning
Track versions of code, data, and models.
- Git – Code versioning
- DVC – Data and model versioning
- MLflow – Model versioning and tracking
- Weights & Biases – Experiment tracking
2. Training
Model development, experimentation, and tuning.
- TensorFlow, PyTorch, Scikit‑learn
- MLflow – Run tracking and logging
- Weights & Biases – Hyperparameter tuning, metrics
- Keras Tuner, Optuna – HPO
3. Orchestration
Automate and manage ML workflows and pipelines.
- Apache Airflow – General orchestration
- Kubeflow Pipelines – K8s‑native ML pipelines
- Argo Workflows – Container‑native orchestration
- MLflow Projects, Metaflow
4. Deployment
Serve trained models for real‑time or batch inference.
- Seldon Core, KServe – K8s serving
- TensorFlow Serving
- MLflow Models, BentoML
- SageMaker – Managed deploy
5. Monitoring
Monitor model performance, detect drift, and ensure reliability.
- Prometheus & Grafana
- Evidently AI, WhyLabs, Arize AI
- SageMaker Model Monitor
In‑Depth: Popular Tools
1) MLflow — Tracking, Registry, Deployment
Manage the ML lifecycle: experiments, reproducibility, and model serving.
- Tracking: log params, metrics, artifacts
- Projects: package ML code
- Models & Registry: package, version, promote
import mlflow
with mlflow.start_run():
mlflow.log_param("alpha", 0.5)
mlflow.log_metric("rmse", 0.78)
# mlflow.sklearn.log_model(model, "model")
2) DVC — Data & Model Versioning
Git‑compatible versioning for datasets, models, and pipelines.
- Version control for datasets
- Pipelines and reproducibility
- Remote storage (S3, GCS, Azure)
# Initialize DVC
dvc init
# Track dataset
dvc add data/train.csv
git add data/train.csv.dvc .gitignore
git commit -m "Add training data"
# Push data to remote storage
dvc remote add -d myremote s3://ml-data-store
dvc push
3) Kubeflow — End‑to‑End on Kubernetes
Cloud‑native platform for pipelines, training, and serving on K8s.
@dsl.pipeline(
name='Basic pipeline',
description='An example pipeline.'
)
def basic_pipeline():
op = dsl.ContainerOp(
name='echo',
image='alpine',
command=['echo', 'Hello Kubeflow!']
)
4) Apache Airflow — Workflow Orchestration
Programmatically author, schedule, and monitor workflows.
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def train_model():
print("Training model...")
def evaluate_model():
print("Evaluating model...")
dag = DAG('ml_pipeline', start_date=datetime(2023, 1, 1), schedule_interval='@daily')
train = PythonOperator(task_id='train', python_callable=train_model, dag=dag)
evaluate = PythonOperator(task_id='evaluate', python_callable=evaluate_model, dag=dag)
train >> evaluate
5) Amazon SageMaker — Managed ML Platform
Build, train, and deploy ML models at scale with AWS.
from sagemaker.sklearn.estimator import SKLearn
sklearn = SKLearn(entry_point='train.py',
role='SageMakerRole',
instance_type='ml.m5.large')
sklearn.fit()
predictor = sklearn.deploy(instance_type='ml.m5.large', initial_instance_count=1)
6) Google Vertex AI — Unified ML Platform
GCP's platform for AutoML, custom training, pipelines, and monitoring.
from google.cloud import aiplatform
aiplatform.init(project='my-project', location='us-central1')
job = aiplatform.CustomTrainingJob(
display_name='my-training-job',
script_path='train.py',
container_uri='gcr.io/cloud-aiplatform/training/tf-cpu.2-2:latest',
requirements=['pandas']
)
model = job.run(replica_count=1, model_display_name='my-model')
Challenges
- Create a visual diagram mapping tools to lifecycle stages.
- Write: "MLflow vs SageMaker — Which to start with and why?"
- Install MLflow locally and log a dummy metric.
- Create a DVC pipeline to version a small CSV dataset.