 Data Versioning with DVC – Reproducible ML Starts with Data
Data Versioning with DVC – Reproducible ML Starts with Data
Version your datasets alongside code to make ML experiments reproducible, collaborative, and production‑ready.
Overview
We should learn Data Versioning with DVC to enable reproducible ML workflows and ensure consistent, trackable datasets across environments. It bridges the DevOps mindset with data‑driven development by version‑controlling data like code, improving collaboration and automation.
Tip: Use + / − or Ctrl + Mouse Wheel to zoom. Scroll to pan.
Learning Resources
Key Learnings
- Why versioning datasets is as important as versioning code.
- How DVC integrates with Git for end‑to‑end reproducibility.
- Track datasets, models, and pipelines with DVC.
- Set up DVC, connect remote storage, manage large files.
- Enable collaboration by standardizing data + code versioning.
What is Data Versioning?
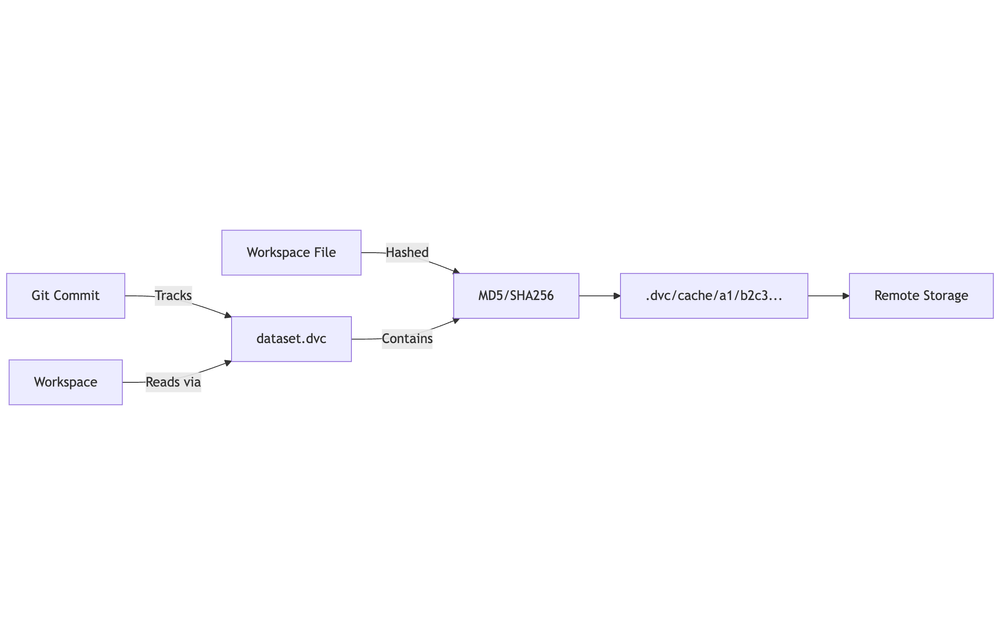
Data Versioning tracks and controls changes to datasets across the ML lifecycle—similar to how Git tracks code. It provides history, comparison, and rollback for the data that drives models.
Tools Used for Data Versioning
| Tool | Description |
|---|---|
| DVC (Data Version Control) | Git‑like version control for datasets and models. |
| LakeFS | Git‑style versioning on object stores like S3. |
| Pachyderm | Data lineage with versioning built into pipelines. |
| Weights & Biases / MLflow | Track dataset artifacts and metadata with experiments. |
Why Version Datasets?
- Reproducibility — Datasets define model behavior; versioning enables auditability and repeatable results.
- Experiment Tracking — Compare models across dataset iterations and ensure correct attribution.
- Collaboration — Keep teams aligned with shared, consistent data versions and branchable workflows.
- Model Monitoring — Tie performance changes to data changes and roll back when needed.
- Production Consistency — Guarantee training/serving use the intended dataset version.
- Compliance & Auditing — Maintain traceable data lineage for regulated environments.
What is DVC?
DVC is an open‑source tool to track, version, and manage data, models, and ML pipelines while working alongside Git.
Why DVC?
- Large datasets don’t belong in Git repos; DVC manages them efficiently.
- Reproducibility and lineage across dynamic data and experiments.
- Team collaboration on data + code with consistent workflows.
What DVC provides
- Data & model versioning with lightweight Git‑tracked metafiles.
- Pipelines (dvc.yaml) to define stages and dependencies.
- Remote storage sync: S3, GCS, Azure, SSH, etc.
- Experiment tracking integrated with your code and data.
- Tight Git integration for full project versioning.
Install DVC
Windows
pip install dvc
# or
choco install dvc # run PowerShell as Administrator
# or
conda install -c conda-forge dvc
Linux
pip install dvc
# or with extras
pip install "dvc[gdrive,ssh]"
# or
snap install dvc --classic
# or
conda install -c conda-forge dvc
macOS
brew install dvc
# or
pip install dvc
# or with S3 support
pip install "dvc[s3]"
Verify
dvc --version
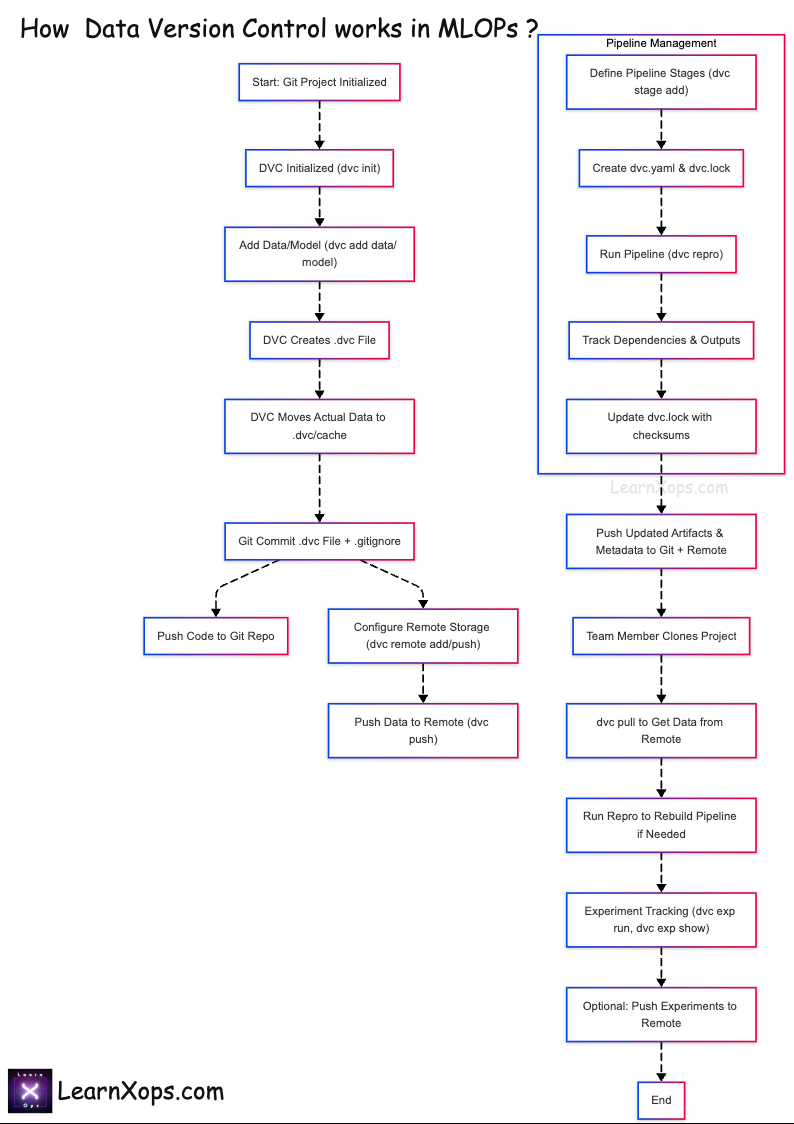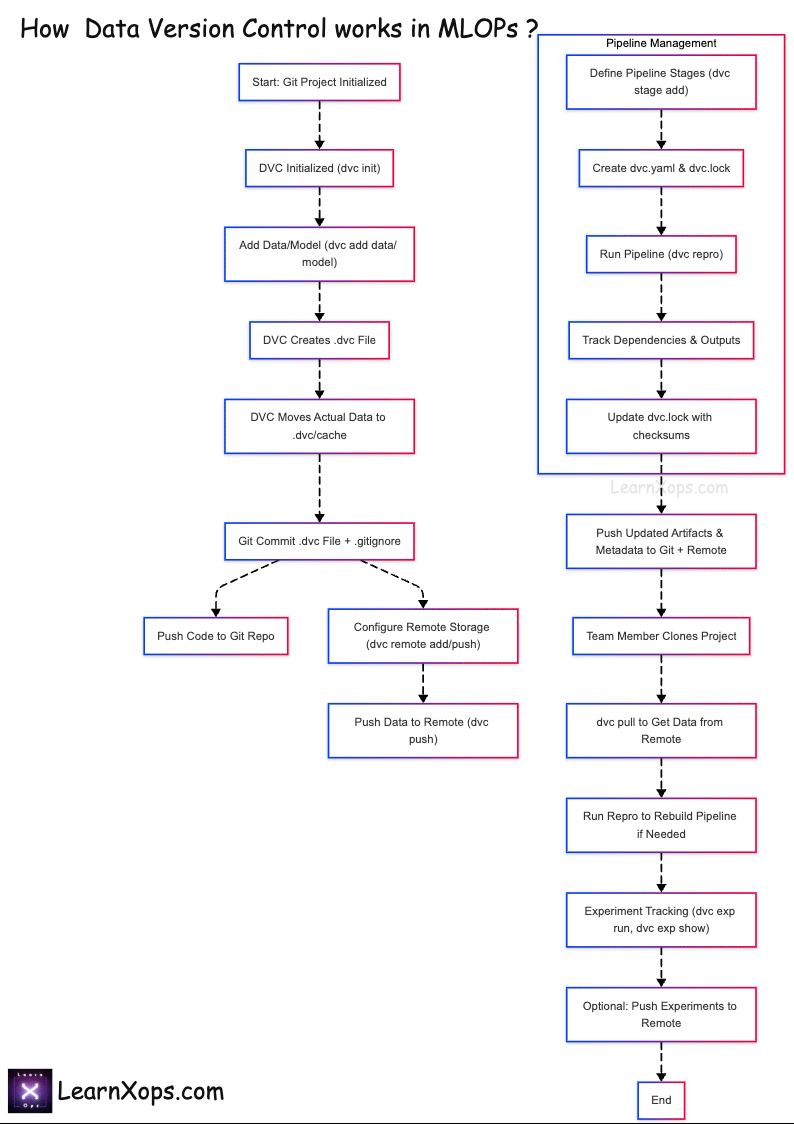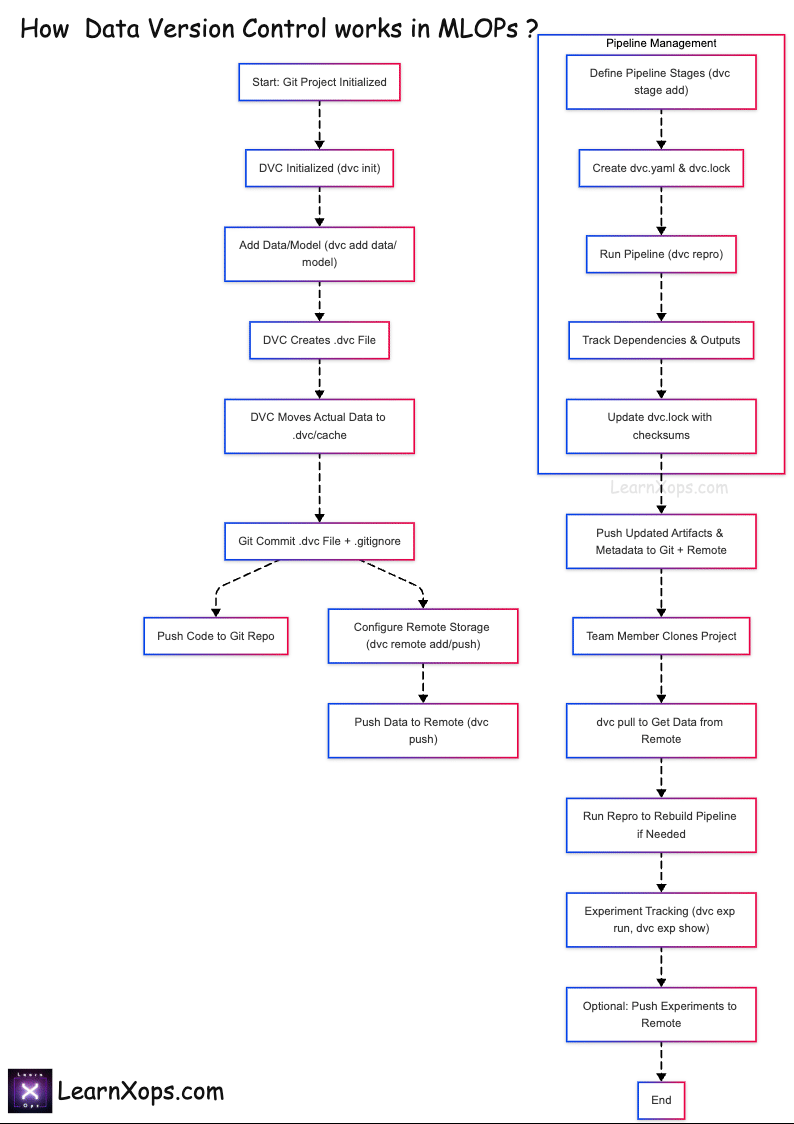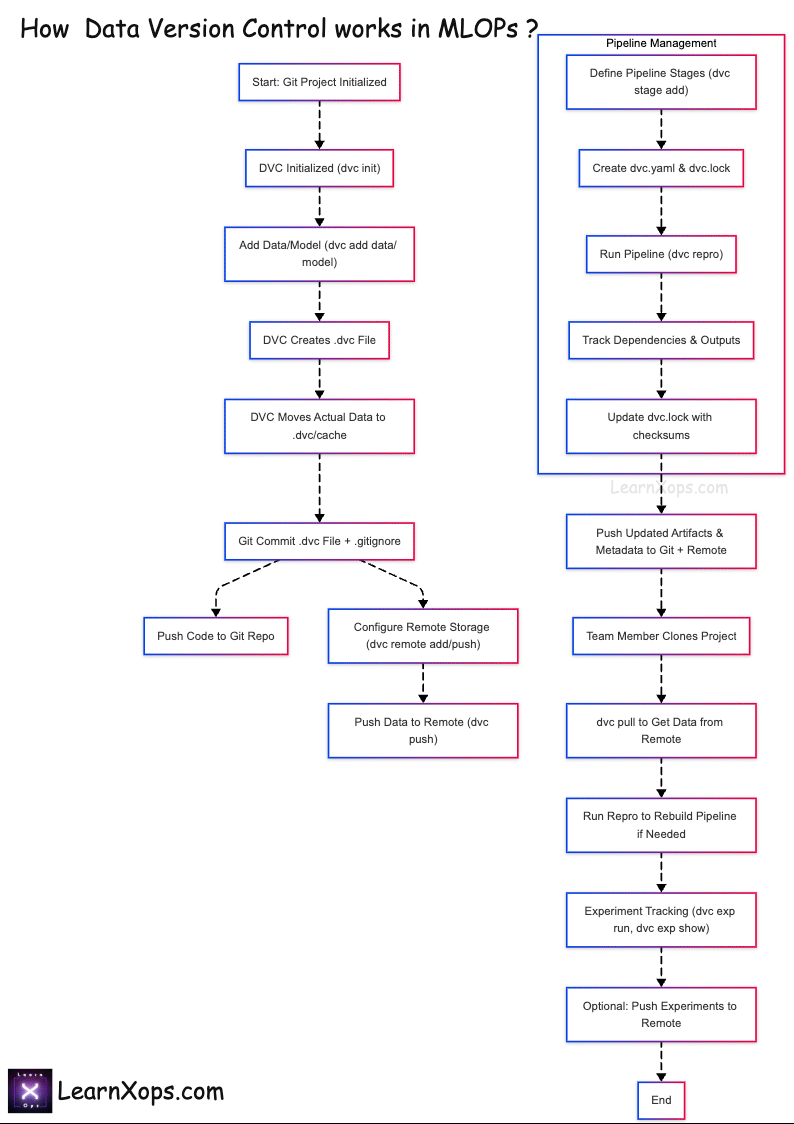
How DVC Works
Core Concept
- Git tracks code and DVC metafiles (.dvc, dvc.yaml, dvc.lock).
- DVC tracks large data and model artifacts in remote storage.
Workflow Integration
- Git stores pipeline definitions; DVC stores data remotely.
- Teammates use
dvc pullto fetch data anddvc reproto rebuild pipelines.
Quickstart
git init
dvc init
git commit -m "Initialize Git and DVC"
# Track data
mkdir -p data
# put a dataset into data/raw_data.csv
dvc add data/raw_data.csv
git add data/raw_data.csv.dvc .gitignore
git commit -m "Track raw data with DVC"
Remote Storage
# Configure default remote
# Example with S3
# dvc remote add -d myremote s3://mybucket/dvcstore
# dvc push
Track Models
# After training
mkdir -p models
mv model.pkl models/model.pkl
dvc add models/model.pkl
git add models/model.pkl.dvc models/.gitignore
git commit -m "Track ML model with DVC"
# dvc push
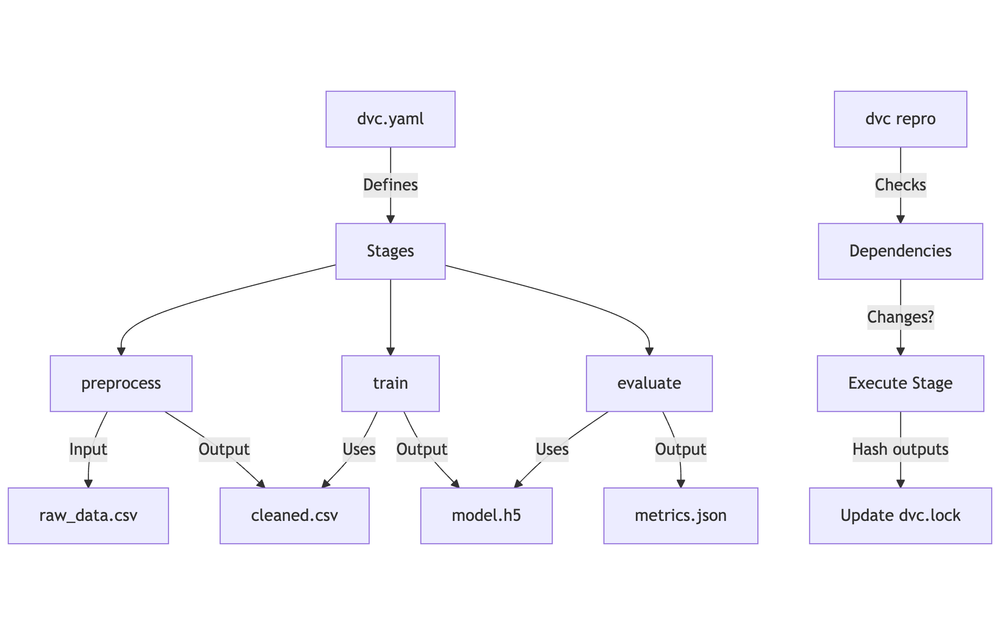
Define & Reproduce Pipelines
# Add preprocess stage
dvc run -n preprocess \
-d data/raw_data.csv -o data/processed \
python scripts/preprocess.py
git add dvc.yaml dvc.lock
git commit -m "Add preprocess stage to pipeline"
# Add training stage
dvc run -n train_model \
-d src/train.py -d data/raw-dataset.csv \
-o models/model.pkl \
python src/train.py data/raw-dataset.csv models/model.pkl
# Rerun when inputs change
dvc repro
# Visualize dependencies
dvc dag
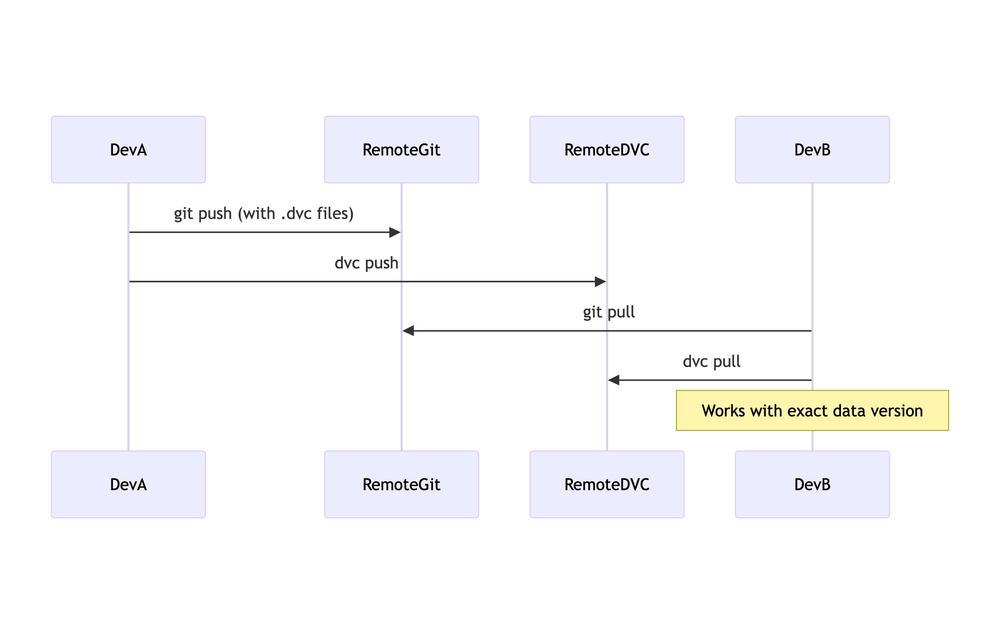
Collaborate: git pull then dvc pull to fetch required data and models.
Benefits for Reproducibility
- Data + Code Coupling with Git and DVC metadata.
- Exact lineage captured in
dvc.lockfor inputs/outputs/commands. - Reliable team workflows by syncing Git repo and DVC remote.
- Modular pipelines with clear stages (preprocess, train, evaluate).
Challenges
- Set up DVC in a Git‑based ML project.
- Add and track a dataset using
dvc add. - Commit and push changes to GitHub and your DVC remote.
- Clone the project elsewhere and use
dvc pullto reproduce. - Write a README section explaining DVC usage in your project.
- Configure S3 or GCS as a remote and push/pull data.