 Managing Large Language Models (LLMs) in Production
Managing Large Language Models (LLMs) in Production
Deploying and maintaining large language models requires specialized workflows for scalability, versioning, latency optimization, and cost control. Mastering these practices ensures reliable inference, continuous improvement, and secure integration of LLMs into real-world applications.
📚 Key Learnings
- What makes LLMs different from traditional ML models
- Fine-tuning vs prompt engineering
- Deployment patterns for LLMs (real-time vs batch, on-demand vs always-on)
- Managing GPU infrastructure and resource scheduling
- Logging, monitoring, and scaling LLM inference
- Cost-saving strategies using model distillation, quantization, and caching
- Serve LLM using tools like vLLM, Hugging Face Inference, OpenLLM, and Ray Serve
Inference & Deployment
Inference
- Can be done via APIs (e.g., OpenAI, Hugging Face)
- Requires GPU or specialized inference hardware
Deployment Strategies
- On cloud: using SageMaker, Vertex AI, Azure ML
- On-prem: using NVIDIA Triton, ONNX Runtime
- Edge deployment: using quantized/distilled models
Challenges and Risks
- Bias in training data
- Hallucination (confidently wrong outputs)
- High computational cost
- Privacy & security concerns
- Regulation & ethical use
Tools and Ecosystem
- Hugging Face Transformers
- LangChain
- OpenAI API
- LlamaIndex
- DeepSpeed, vLLM for fast inference
- Weights & Biases / MLflow for experiment tracking
Fine-Tuning Techniques for LLMs – LoRA, QLoRA, PEFT, and Adapters
Fine-tuning Large Language Models (LLMs) can be resource-intensive due to their size. To make this process more efficient, several parameter-efficient techniques have emerged. Let's explore popular fine-tuning strategies: LoRA, QLoRA, PEFT, and Adapters, highlighting how they work and when to use them.
Why Fine-Tuning Matters
- Aligns models with domain-specific tasks or datasets.
- Improves performance on specialized tasks without retraining the entire model.
- Reduces inference latency and improves control over outputs.
Core Techniques
1. 🔧 LoRA (Low-Rank Adaptation)
| Aspect | Detail |
|---|---|
| Purpose | Efficient fine-tuning using low-rank matrix updates |
| Method | Injects trainable low-rank matrices into frozen layers |
| Pros | Lightweight, fast training, reduces GPU memory usage |
| Use Cases | Chatbots, domain-specific LLM tuning |
| Libraries | peft (Hugging Face), lora (FastChat) |
from peft import get_peft_model, LoraConfig
peft_config = LoraConfig(task_type="CAUSAL_LM", r=8, lora_alpha=32, lora_dropout=0.1)
model = get_peft_model(base_model, peft_config)QLoRA (Quantized LoRA)
| Aspect | Detail |
|---|---|
| Purpose | LoRA + quantization (4-bit or 8-bit) for memory efficiency |
| Method | Uses 4-bit quantized weights + LoRA adapters |
| Pros | Run large models on a single GPU, 2-4x memory savings |
| Use Cases | Fine-tuning 65B models on consumer GPUs |
| Libraries | bitsandbytes, transformers, peft |
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_use_double_quant=True)
model = AutoModelForCausalLM.from_pretrained("model_name", quantization_config=bnb_config)PEFT (Parameter-Efficient Fine-Tuning)
| Aspect | Detail |
|---|---|
| Purpose | Umbrella framework for techniques like LoRA, Prompt Tuning |
| Method | Train only a small subset of model parameters |
| Pros | Unified API, scalable for many models |
| Use Cases | Low-resource environments, multi-task setups |
| Libraries | Hugging Face peft |
from peft import prepare_model_for_kbit_training
model = prepare_model_for_kbit_training(model)Adapters
| Aspect | Detail |
|---|---|
| Purpose | Plug-in modules injected into transformer layers |
| Method | Train small adapter layers; leave backbone frozen |
| Pros | Modular, reusable across tasks, fast training |
| Use Cases | Multi-task fine-tuning, federated setups |
| Libraries | AdapterHub, Hugging Face Adapters |
from transformers import AdapterConfig
adapter_config = AdapterConfig(mh_adapter=True, output_adapter=True)
model.add_adapter("my_task", config=adapter_config)Comparison Table
| Technique | Memory Efficient | Modular | Suitable for Low-resource | Easy to Implement |
|---|---|---|---|---|
| LoRA | ✅ | ⚠️ | ✅ | ✅ |
| QLoRA | ✅✅ | ⚠️ | ✅✅ | ⚠️ |
| PEFT | ✅ | ✅ | ✅✅ | ✅✅ |
| Adapters | ✅ | ✅✅ | ✅ | ⚠️ |
When to Use What?
| Scenario | Suggested Method |
|---|---|
| Limited GPU memory | QLoRA |
| Training same model on multiple tasks | Adapters |
| Need fastest training and inference | LoRA |
| Want general-purpose framework | PEFT |
Fine-Tuning vs Prompt Engineering
| Aspect | Fine-Tuning | Prompt Engineering |
|---|---|---|
| Definition | Modifying model weights using labeled data | Crafting inputs to guide model behavior |
| Effort Required | High (data prep, training, infra) | Low to moderate (text input crafting) |
| Cost | Expensive (compute, storage) | Inexpensive, especially with hosted models |
| Latency | Slightly higher due to larger models | Same as base model |
| Customization | Deep, task-specific customization | Shallow, context-based adjustments |
| Repeatability | Consistent once trained | May vary with prompt changes |
| Use Cases | Domain adaptation, enterprise apps | Quick prototyping, dynamic interactions |
| Tooling | Requires training frameworks (LoRA, PEFT, etc.) | No-code or simple API-based |
| Deployment | Host fine-tuned model manually | Use SaaS APIs like OpenAI, Claude, etc. |
| Best For | High-accuracy & large-scale production tasks | Fast iteration, experimentation, few-shot tasks |
What Makes LLMs Different from Traditional ML Models
Large Language Models (LLMs) like GPT, BERT, LLaMA, and Claude represent a new generation of AI systems capable of understanding and generating human-like language at scale. Let's explore how LLMs differ from traditional machine learning (ML) models, especially in terms of architecture, training, capabilities, and use cases.
Key Differences
| Aspect | Traditional ML Models | Large Language Models (LLMs) |
|---|---|---|
| Purpose | Solve narrow tasks (classification, etc.) | General-purpose language understanding & generation |
| Input | Structured/tabular/numerical data | Natural language text |
| Architecture | Decision Trees, SVMs, Logistic Regression | Transformers with attention mechanisms |
| Training Data | Task-specific datasets (often small) | Massive corpus of unstructured text (web, books) |
| Model Size | Thousands to millions of parameters | Billions to trillions of parameters |
| Generalization | Limited to trained tasks | Few-shot, zero-shot, and transfer learning capable |
| Pre-training | Rare; models trained from scratch | Pre-trained on large corpus, fine-tuned for tasks |
| Compute Requirement | Low to moderate | Extremely high (requires GPU/TPU clusters) |
| Inference | Fast and lightweight | Slower and resource-intensive |
| Explainability | Easier to interpret (e.g., decision paths) | Harder to interpret; black-box behavior |
Examples
Traditional ML Model:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)LLM (Using OpenAI's GPT):
import openai
openai.api_key = "YOUR_API_KEY"
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": "Explain quantum physics in simple terms"}]
)
print(response['choices'][0]['message']['content'])Use Cases Comparison
| Task | Traditional ML Model | LLM |
|---|---|---|
| Sentiment Analysis | Logistic Regression on TF-IDF | Fine-tuned GPT or BERT |
| Price Prediction | Linear Regression | Not a strong fit |
| Text Summarization | Not ideal | GPT, T5, LLaMA |
| Fraud Detection | Random Forest / XGBoost | Can assist in explanation/report generation |
| Chatbot | Rule-based/NLU + ML classifiers | Fully powered conversational LLMs |
| Code Generation | Not applicable | Codex, Code LLaMA, DeepSeek-Coder |
Why LLMs Matter
- Enable natural human-computer interaction.
- Can perform multiple tasks without retraining.
- Power modern AI assistants, search engines, and copilots.
- Capable of creative tasks like writing, coding, and design.
Challenges of LLMs
- High cost of training and inference
- Hallucinations and factual inaccuracies
- Difficulty in fine-tuning and alignment
- Data privacy and ethical concerns
When to Use LLMs vs Traditional ML
| Situation | Recommended Model Type |
|---|---|
| Structured data tasks | Traditional ML |
| Resource-constrained environments | Traditional ML |
| Open-ended or text-based tasks | LLM |
| Need for generalization | LLM |
Deployment Patterns for Large Language Models (LLMs)
Deploying LLMs efficiently and cost-effectively requires choosing the right deployment pattern based on use case, latency requirements, resource constraints, and user interaction patterns. Let's compare common deployment patterns like real-time vs batch and on-demand vs always-on, highlighting their trade-offs and applications.
Core Deployment Dimensions
1. Real-Time vs Batch
| Dimension | Real-Time Inference | Batch Inference |
|---|---|---|
| Latency | Low-latency (<1s), instant response | High-latency, processed on schedule |
| Use Cases | Chatbots, search, live support, autocomplete | Report generation, summarization, analytics |
| Trigger | User/API request | Scheduled jobs, data triggers |
| Compute Cost | Higher (scaled per request) | Lower per request, but possibly higher peak |
| Scalability | Needs autoscaling | Can batch process at off-peak times |
| Example | GPT-powered assistant in web app | Weekly email summarizer for CRM records |
2. On-Demand vs Always-On
| Dimension | On-Demand (Cold Start) | Always-On (Warm Start) |
|---|---|---|
| Startup Time | Slower (seconds to minutes) | Fast (sub-second latency) |
| Cost | Cost-efficient for infrequent usage | Costly but high-performance |
| Use Cases | DevOps tools, infrequent endpoints | High-traffic chatbots, customer service |
| Infra Style | Serverless, function-as-a-service | Dedicated GPU/TPU-backed containers |
| Trade-offs | Latency during startup | Idle costs, scaling complexity |
| Example | Lambda function calling OpenAI API | Kubernetes pod serving LLM via FastAPI |
Hybrid Patterns
Many production systems use a combination of these patterns:
- Batch + Always-On: LLM processes batch requests continuously on dedicated infra.
- Real-Time + On-Demand: Cost-saving pattern for dev/test environments.
- Real-Time + Always-On with Auto-Scaling: Ideal for SaaS/production chatbots.
Infrastructure & Tooling Examples
| Tool/Platform | Use Case | Deployment Style |
|---|---|---|
| AWS SageMaker | Batch & real-time | Batch Transform / Endpoint |
| Vertex AI | Real-time APIs | AutoML / Deployed Model |
| OpenAI API | Real-time, on-demand | Fully managed SaaS |
| BentoML | Real-time LLM serving | On Docker / Kubernetes |
| VLLM / TGI | High-throughput inference | Always-on with GPU optimization |
| FastAPI + HuggingFace | Custom REST API | On-Demand / Always-On |
Choosing the Right Pattern
| Criteria | Recommended Pattern |
|---|---|
| High throughput, low latency | Real-Time + Always-On |
| Cost-sensitive and infrequent | On-Demand + Batch |
| Daily scheduled text processing | Batch |
| Multi-user customer support | Always-On + Auto-Scaling |
| Dev/test & experimentation | On-Demand / Serverless |
Managing GPU Infrastructure and Resource Scheduling
Efficiently managing GPU infrastructure is critical for high-performance AI workloads like training and deploying LLMs.
Core Components of GPU Infrastructure
| Component | Description |
|---|---|
| GPU Hardware | NVIDIA A100, V100, H100, L4, AMD Instinct, etc. |
| Server Nodes | On-prem servers, AWS EC2, GCP GPU VMs, Azure NC/ND-series VMs |
| Orchestration | Kubernetes (with NVIDIA device plugin), Slurm, Ray, Nomad |
| Storage | High-speed parallel file systems (NVMe, EFS, FSx, Ceph) |
| Networking | High-bandwidth interconnects (InfiniBand, 100Gbps Ethernet) |
Resource Scheduling Models
- Static Allocation
Assign specific GPUs to workloads.
Simpler but underutilizes resources. - Dynamic Scheduling
Pool of GPUs shared across workloads.
Requires schedulers (K8s, Slurm, Ray). - Multi-Tenancy & Quotas
Enforce GPU limits per user/team.
Namespace-based GPU quota management in Kubernetes. - Priority & Preemption
Schedule critical jobs with higher priority.
Evict lower-priority workloads if needed.
Kubernetes GPU Scheduling
Prerequisites:
- NVIDIA GPU Drivers installed
- nvidia-device-plugin DaemonSet
Sample YAML for GPU Request:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvidia/cuda:11.0-base
resources:
limits:
nvidia.com/gpu: 1 # request 1 GPUKey Tools:
- Kueue – workload queueing for batch workloads
- Volcano – batch job scheduler
- Kubeflow – ML workflows with GPU support
Monitoring & Optimization
| Tool | Purpose |
|---|---|
| NVIDIA DCGM | GPU telemetry and health |
| Prometheus + Grafana | Resource metrics dashboard |
| nvidia-smi | CLI for real-time GPU usage |
| Kubecost | GPU cost tracking and forecasting |
| MIG (Multi-Instance GPU) | Partition A100s into logical GPUs |
💡 Best Practices
- Use MIG for fine-grained isolation.
- Auto-scale GPU nodes with Karpenter or Cluster Autoscaler.
- Use mixed precision (FP16/BF16) to reduce compute time.
- Separate training and inference nodes for cost efficiency.
- Implement GPU quota policies per team/project.
Cloud Provider Considerations
| Cloud | Key Features |
|---|---|
| AWS | EC2 P4/P5/A10G, SageMaker, FSx Lustre |
| GCP | T4/V100/A100 support, Vertex AI |
| Azure | NC/ND-series, AKS + GPU Pools |
Experiment Management
- Use MLFlow or Weights & Biases for logging GPU-based experiments.
- Label GPU-intensive jobs for visibility (job-type=gpu)
- Leverage node affinity/taints to isolate GPU workloads.
🧠 Learn here
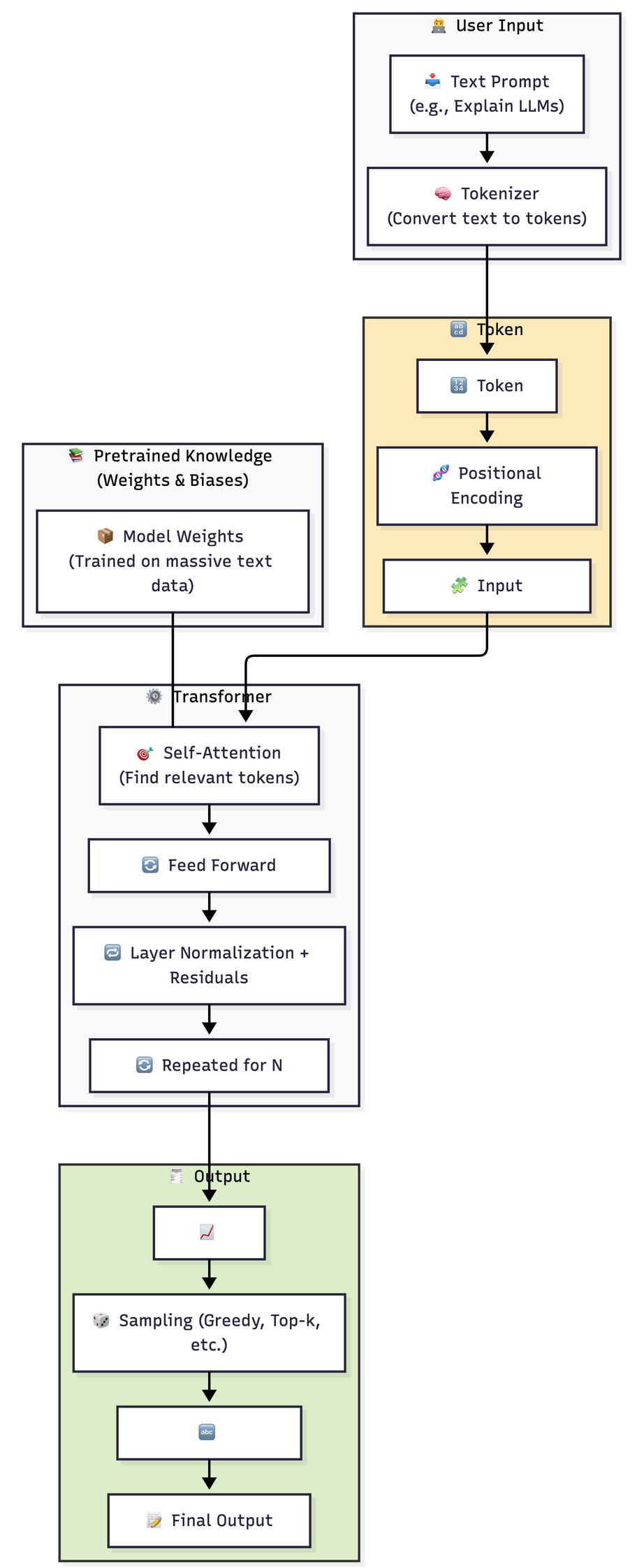
What is an LLM, a.k.a Large Language Model?
A Large Language Model is a transformer-based neural network trained on massive corpora of textual data to perform various NLP tasks. These models predict the next word in a sentence, generate responses, summarize content, translate languages, and more.
In Simple words:
- Large Language Models (LLMs) are advanced deep learning models trained on vast amounts of text data
- They can understand, generate, and manipulate human-like language
Core Concepts
- Transformers
Introduced by Vaswani et al. in 2017
Uses self-attention mechanisms
Enables parallelization during training - Tokenization
Text is broken down into smaller units (tokens)
Byte Pair Encoding (BPE), WordPiece, SentencePiece used - Pretraining and Fine-Tuning
Pretraining: Unsupervised learning on large corpora
Fine-tuning: Supervised training on specific tasks - Embeddings
Converts tokens to dense vectors
Captures syntactic and semantic meaning - Attention Mechanism
Allows model to focus on relevant parts of input
Scaled dot-product attention is key
Architecture
- Embedding Layer: Converts token IDs into vectors
- Transformer Blocks: Stack of attention + feedforward layers
- Language Head: Outputs probabilities over vocabulary
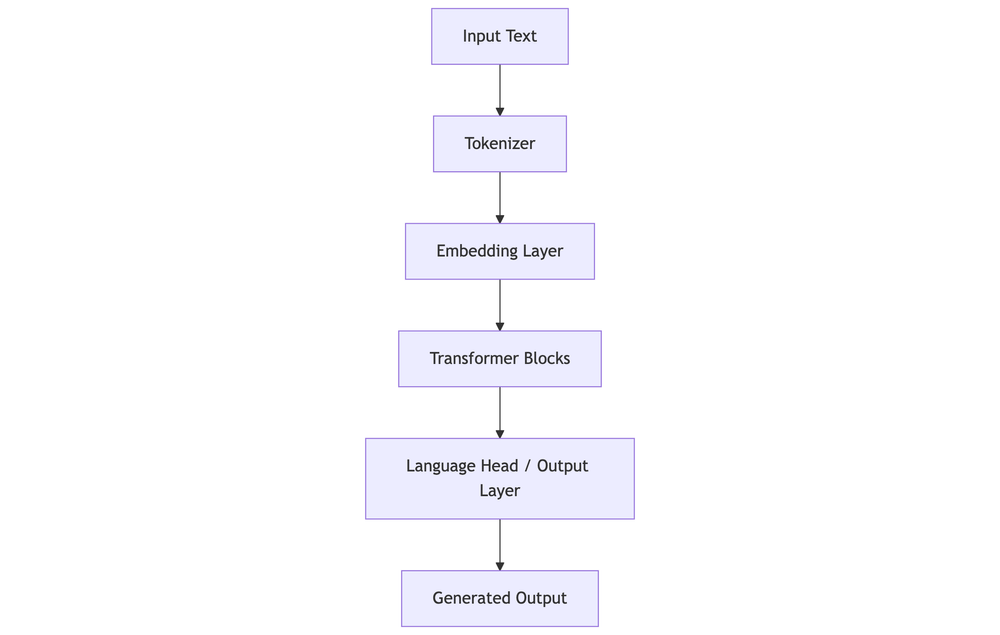
Training Process
- Collect Large Text Corpus
- Tokenize Input
- Train with Masked Language Modeling or Causal LM
- Apply Optimization Techniques (Adam, Learning Rate Schedulers)
- Fine-tune on downstream tasks
Popular LLMs
| Model | Developer | Parameters | Notable Feature |
|---|---|---|---|
| GPT-3 | OpenAI | 175B | Few-shot learning |
| PaLM 2 | 540B | Multilingual, reasoning | |
| LLaMA 2 | Meta | 7B-65B | Open-weight LLMs |
| Claude | Anthropic | Proprietary | Constitutional AI |
| Mistral | Mistral AI | 7B | Efficient, open-weight |
| Falcon | TII | 7B-180B | High performance in open LLMs |
Model Sizes, Training Requirements, and Memory Needs
| Model Size | Parameters | Training Data Size | GPU Requirements | Memory (VRAM) Needed |
|---|---|---|---|---|
| Small | ~125M | ~10GB | Single GPU (e.g., RTX 3090) | ~8-16 GB |
| Medium | ~1.3B | ~50GB | 2-4 GPUs (A100/3090) | ~24-40 GB |
| Large | ~6-13B | ~300GB | 8+ A100 GPUs | 80+ GB |
| XL | 30B+ | 500GB+ | 16-32 A100 GPUs | 160+ GB |
| XXL | 65B-540B | 1TB+ | TPU Pods / Supercomputers | 500 GB+ |
Use Cases
- Text summarization
- Chatbots & conversational agents
- Code generation
- Sentiment analysis
- Translation
- Content creation
- Legal/medical document analysis
Logging, Monitoring, and Scaling LLM Inference
Deploying LLMs in production environments demands robust observability and elastic scalability.
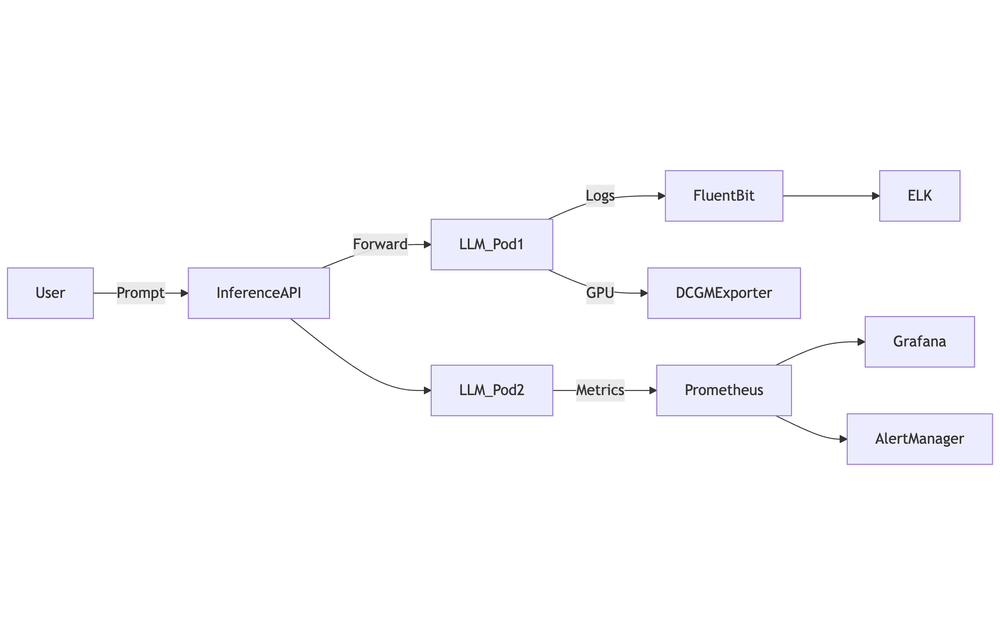
Logging LLM Inference
Key Aspects to Log
| Metric | Description |
|---|---|
| Request Metadata | Timestamp, user ID, session ID, request ID |
| Input Prompts | (Masked/anonymized) user prompts |
| Model Version | Track changes over deployments |
| Response Latency | Time from request to model output |
| Tokens Used | Prompt + completion token count |
| Errors/Failures | Timeout, 5xx, invalid prompt, token limit exceeded |
Logging Tools
- OpenTelemetry + Fluent Bit: Unified telemetry and log pipelines
- ELK Stack (Elasticsearch, Logstash, Kibana)
- Cloud-native solutions: CloudWatch, GCP Logging, Azure Monitor
{
"timestamp": "2025-08-02T10:32:00Z",
"model": "gpt-4",
"prompt": "Translate to French: 'Hello'",
"response_time_ms": 218,
"tokens": 15,
"status": "success"
}Monitoring LLM Inference
Metrics to Track
| Category | Key Metrics |
|---|---|
| Performance | Inference latency, throughput (req/s), queue time |
| System Health | GPU/CPU utilization, memory usage, disk I/O |
| Model Behavior | Token counts, prompt lengths, temperature/output stats |
| Error Monitoring | 4xx/5xx status codes, timeout rate, fallbacks |
Monitoring Stack
- Prometheus + Grafana
- NVIDIA DCGM Exporter (GPU metrics)
- OpenTelemetry Metrics Collector
- Sentry / Datadog (for alerting & error tracking)
Scaling LLM Inference
1. Horizontal Scaling
- Add more inference pods/containers
- Use Kubernetes Horizontal Pod Autoscaler (HPA)
- Metrics: CPU/GPU load, QPS, latency
2. Vertical Scaling
- Allocate more GPU/CPU resources per replica
- Upgrade to high-memory instances or A100/H100
3. Model Optimization
| Technique | Benefit |
|---|---|
| Quantization | Reduce memory and speed up inference |
| vLLM/TGI | Efficient transformer inference engine |
| Batch Inference | Serve multiple requests in one pass |
| Async Pipelines | Reduce bottlenecks using asyncio/queues |
4. Load Balancing
- Use service mesh (Istio/Linkerd) or K8s Ingress + HPA
- Ensure intelligent request routing to least-loaded replica
Cost-Saving Strategies for LLM Inference – Distillation, Quantization, and Caching
Running large language models (LLMs) in production can be expensive due to compute, storage, and latency demands. Let's explore three effective strategies to reduce cost while maintaining acceptable performance: Model Distillation, Quantization, and Caching.
1. Model Distillation
Train a smaller "student" model to replicate the behavior of a larger "teacher" model by mimicking its outputs.
Benefits
- Reduced model size (2x–20x smaller)
- Faster inference
- Lower compute/GPU requirements
Use Cases
- On-device applications
- Low-latency chatbots
- Edge deployments
Tools
- Hugging Face Transformers (distilBERT, TinyBERT)
- Knowledge Distillation libraries (e.g., DistilLLM, TinyStories)
# Example: Teacher-student setup with HuggingFace
from transformers import AutoModelForSequenceClassification
teacher_model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
student_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")2. Model Quantization
Reduce the precision of model weights from 32-bit floating point (FP32) to 8-bit or 4-bit integers (INT8, INT4).
Benefits
- Smaller memory footprint (up to 4x reduction)
- Faster inference speed
- Lower power and storage usage
Trade-offs
- Slight reduction in accuracy
- Quantization-aware training improves results
Tools
- bitsandbytes, Optimum, TensorRT, ONNX Runtime
- Hugging Face Transformers integration
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained("gpt2", quantization_config=bnb_config)3. Caching Inference Results
Store and reuse responses to frequent or identical queries to avoid redundant inference.
Benefits
- Zero computation for cache hits
- Reduces token usage and latency
Use Cases
- Chatbots answering FAQs
- Repeated prompt inputs
- Search/autocomplete services
Types of Caching
| Type | Example |
|---|---|
| Prompt-Response | Full response caching for known prompts |
| Output Tokens | Cache token sequences during generation |
| Embedding Cache | Cache vector results in RAG pipelines |
Tools
- Redis, Memcached
- Faiss/Weaviate for embedding caches
- Custom prompt-hash cache layers
Combined Strategy Table
| Strategy | Savings Potential | Accuracy Impact | Infra Benefit | Best For |
|---|---|---|---|---|
| Distillation | ✅✅✅ | Moderate | Smaller model sizes | Edge/real-time inference |
| Quantization | ✅✅ | Low/none (w/ Aware) | Faster, smaller | Consumer GPUs, memory-constrained |
| Caching | ✅✅✅ | None | Bypasses model call | FAQs, autocomplete, search, RAG |
🧠 Best Practices
- Use quantized models + caching for high-volume endpoints.
- Perform benchmarking after distillation/quantization.
- Regularly update caches and avoid stale content.
- Track hit/miss ratio in caching layer.
Serving LLMs with vLLM, Hugging Face Inference, OpenLLM, and Ray Serve
Efficient LLM deployment requires the right tooling for performance, scalability, and ease of integration. Let me explain a practical comparison and usage guide for four popular tools: vLLM, Hugging Face Inference Endpoints, OpenLLM, and Ray Serve.
Tool Comparison Table
| Tool | Strengths | Use Cases | Infra Needs |
|---|---|---|---|
| vLLM | Fast throughput, paged attention, multi-models | High-load inference APIs | GPU, Kubernetes |
| Hugging Face Inference | Fully managed, easy to use | Hosted inference, zero ops | HuggingFace Infra |
| OpenLLM | Open-source, REST/gRPC, LoRA adapter support | On-prem, containerized deployments | Docker/K8s |
| Ray Serve | Scalable actor-based deployment | Python-first multi-model microservices | Ray Cluster / K8s |
vLLM (via vllm.ai)
Features
- Transformer engine optimized for LLMs
- Efficient batch serving
- Paged attention for long context support
Installation
pip install vllmLaunch Example
python -m vllm.entrypoints.openai.api_server \
--model facebook/opt-6.7b \
--port 8000Hugging Face Inference Endpoints
Features
- Fully managed GPU endpoints
- Deploy from HF UI or CLI
- Auto-scaling and observability included
Example Deployment
# From CLI
huggingface-cli endpoint create \
--model-id meta-llama/Llama-2-7b-chat-hf \
--instance-type a10g.large \
--name llama2-apiIntegration
from huggingface_hub import InferenceClient
client = InferenceClient(model="meta-llama/Llama-2-7b-chat-hf")
response = client.text_generation("What is Ray Serve?")OpenLLM (by BentoML)
Features
- REST and gRPC API support
- LoRA adapter integration
- Model server CLI with YAML config
Install and Serve
pip install openllm
openllm start dolly-v2 --model-id databricks/dolly-v2-3bDeploy with BentoML
bentoml build && bentoml containerize openllm/dolly-v2Ray Serve
Features
- Actor-based architecture for distributed serving
- Built-in scaling and fault-tolerance
- Python-first deployment via decorators
Basic Example
from ray import serve
from fastapi import FastAPI
app = FastAPI()
@serve.deployment(route_prefix="/generate")
@serve.ingress(app)
class LLMService:
async def __call__(self, request):
prompt = await request.json()
return {"output": "Generated: " + prompt["text"]}
serve.run(LLMService.bind())When to Use What?
| Scenario | Recommended Tool |
|---|---|
| Fully managed, hosted solution | Hugging Face Inference |
| Local inference with multi-GPU efficiency | vLLM |
| Containerized, open-source API deployment | OpenLLM |
| Pythonic microservice model deployment | Ray Serve |
📊 Summary
Today you've learned how to professionally manage large language models (LLMs) in production environments, covering the complete lifecycle from deployment to optimization.
🎯 Key Takeaways
- LLMs have unique requirements for GPU memory, batch processing, and long-context handling
- Inference optimization involves quantization, caching, and efficient serving frameworks
- Deployment strategies range from cloud APIs to containerized on-premise solutions
- Fine-tuning with LoRA/PEFT enables cost-effective model customization
- Comprehensive monitoring includes latency, token usage, and GPU utilization metrics
- Cost optimization through distillation, quantization, and intelligent caching
- Production-ready serving with vLLM, Ray Serve, OpenLLM, or Hugging Face
🔧 Production Considerations
| Aspect | Key Focus Areas |
|---|---|
| Performance | Batch inference, GPU utilization, response latency |
| Scalability | Horizontal/vertical scaling, load balancing, auto-scaling |
| Cost Management | Model compression, caching, efficient hardware utilization |
| Observability | Comprehensive logging, monitoring, alerting, and error tracking |
| Reliability | Fault tolerance, graceful degradation, backup strategies |
💡 Best Practices Recap
- Start small: Begin with smaller models and scale up based on requirements
- Optimize first: Apply quantization and caching before scaling hardware
- Monitor everything: Track both technical metrics and business outcomes
- Plan for costs: LLM inference can be expensive—optimize early and often
- Security focus: Implement proper authentication, rate limiting, and data privacy
🔥 Challenges
- Use a Hugging Face model like distilGPT2 or flan-t5-small to generate output
- Run quantized LLM using bitsandbytes or AutoGPTQ
- Deploy the model as a container using vLLM or OpenLLM on local Docker
- Enable batching for inference to handle multiple requests
- Fine-tune a small LLM using LoRA + PEFT with your own dataset
- Set up CI/CD pipeline to auto-update a deployed LLM model (GitHub Actions + Hugging Face repo or S3)
- Add observability: track latency, input length, token count per request
- Deploy LLM inference to GPU-backed Kubernetes pod (EKS/GKE) using Ray Serve or KServe
- Write and test 5 different prompts and compare responses
- Log prompt + response to file or JSON store