 Disaster Recovery & High Availability for ML Systems
Disaster Recovery & High Availability for ML Systems
We should master Disaster Recovery and High Availability to ensure ML systems remain resilient, minimize downtime, and maintain model performance even during infrastructure failures or unexpected disruptions.
Welcome
Hey ŌĆö I'm Aviraj ¤æŗ
We should master Disaster Recovery and High Availability to ensure ML systems remain resilient, minimize downtime, and maintain model performance even during infrastructure failures or unexpected disruptions.
¤öŚ 30 Days of MLOps
¤ō¢ Previous => Day 28: Cost Optimization & Performance Tuning
¤ōÜ Key Learnings
- Understand the principles of Disaster Recovery (DR) and High Availability (HA) in ML environments
- Identify single points of failure in ML pipelines, APIs, and training workflows
- Learn RPO (Recovery Point Objective) and RTO (Recovery Time Objective) and their implications for ML workloads
- Understand strategies for data redundancy (multi-region storage, replication) and model redundancy (multi-endpoint deployments)
- Explore infrastructure-level HA for ML systems using Kubernetes, cloud load balancers, and managed services
- Design automated failover and disaster recovery runbooks for ML inference services
- Backup & Restore Strategies for ML Assets
¤¦Ā Learn here
Machine Learning (ML) environments are increasingly powering critical applications across industries, from real-time fraud detection to medical diagnostics. Ensuring these systems remain available and recoverable during failures is essential to avoid downtime, data loss, and service disruption.
Let's explore the principles of Disaster Recovery (DR) and High Availability (HA) in the context of ML.
Understanding DR and HA
Disaster Recovery (DR)
A set of policies, tools, and procedures that enable the recovery or continuation of ML services and infrastructure after a disruptive event (e.g., hardware failure, cyberattack, natural disaster).
Why it's needed?
- Minimize downtime after catastrophic failures
- Recover critical ML workloads (training pipelines, inference services, data processing)
- Restore datasets, models, and configurations from secure backups
Core DR Metrics:
- RPO (Recovery Point Objective): Maximum acceptable amount of data loss (time-based)
- RTO (Recovery Time Objective): Maximum acceptable downtime after a failure
DR Strategies for ML:
- Regular backups of datasets, feature stores, and trained models
- Infrastructure-as-Code (IaC) for rapid environment re-provisioning
- Geo-redundant storage for datasets and model artifacts
- Automated failover to secondary clusters
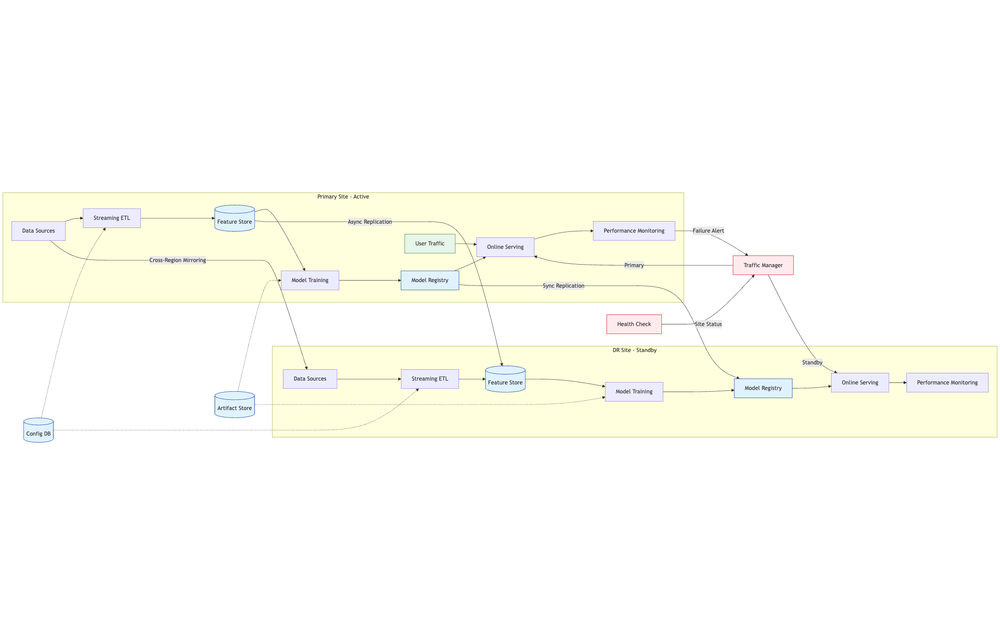
High Availability (HA)
Architectural approach to design ML systems that remain operational with minimal downtime, even in the face of component failures.
Why it's needed?
- Ensure continuous availability of ML services
- Reduce single points of failure in training and inference pipelines
- Maintain SLA (Service Level Agreement) uptime requirements
HA Strategies for ML:
- Load-balanced, multi-instance model inference servers
- Redundant Kubernetes clusters or node pools
- Distributed data storage (e.g., S3, GCS, HDFS with replication)
- Model versioning with safe rollback capabilities
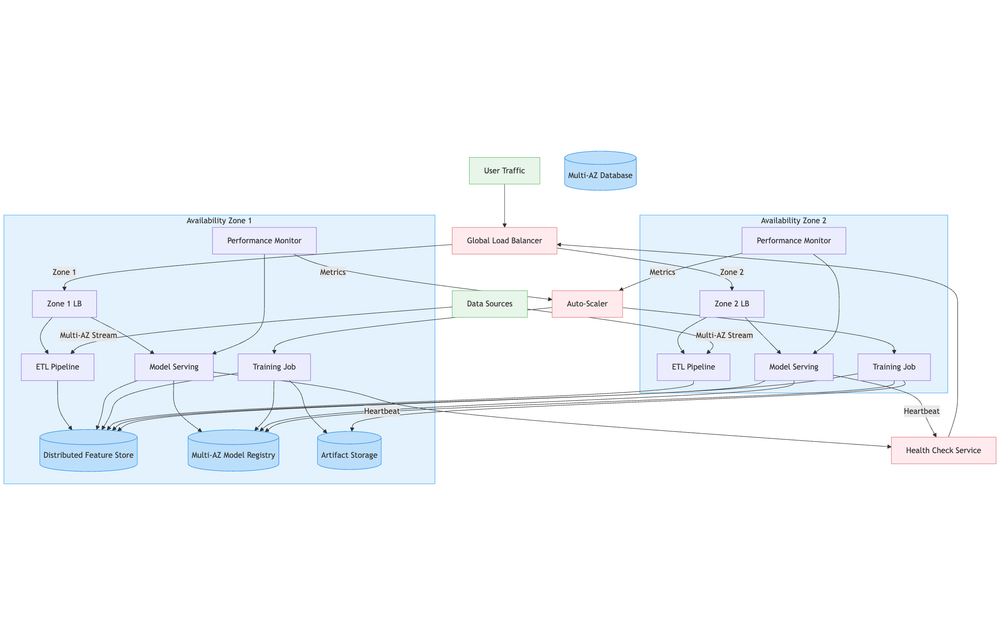
DR vs HA in ML Environments
| Aspect | Disaster Recovery (DR) | High Availability (HA) |
|---|---|---|
| Goal | Recover from outages or disasters | Prevent downtime and keep services running |
| Focus | Restoration post-failure | Continuous operation during failures |
| Timeframe | Reactive (after incident) | Proactive (during operations) |
| Typical RTO | Hours to days | Seconds to minutes |
| Typical Approach | Backups, replication, failover clusters | Redundancy, load balancing, fault tolerance |
Challenges in ML DR & HA
- Large Dataset Recovery: Terabytes of training data can be slow to restore
- Model Synchronization: Keeping model versions consistent across regions
- Pipeline Complexity: Multi-step ML pipelines require orchestrated recovery
- GPU/TPU Availability: Limited hardware availability can delay failover
- Stateful Services: Feature stores and metadata services need consistent backups
Single Points of Failure
A Single Point of Failure (SPOF) is any component in a system whose failure would cause the entire systemŌĆöor a critical part of itŌĆöto stop functioning. In Machine Learning (ML) environments, SPOFs can lead to downtime, loss of productivity, and degraded model performance.
Single Points of Failure in ML Pipelines
ML pipelines typically involve multiple stages such as data ingestion, preprocessing, feature engineering, model training, and deployment.
Common SPOFs:
- Centralized Feature Store: If the feature store is down, training and inference may fail
- Single Data Source: Dependence on one database or storage bucket
- Single Scheduler/Orchestrator Instance: Airflow, Kubeflow, or MLflow orchestrator failures
- Unversioned Datasets: Inability to roll back to known good datasets
- Monolithic Pipeline Code: Changes in one stage break the whole pipeline
Mitigation Strategies:
- Replicate feature stores across zones/regions
- Use redundant data sources
- Deploy orchestrators in HA mode
- Implement dataset versioning (DVC, LakeFS)
- Modularize pipelines with clear stage isolation
Single Points of Failure in ML APIs
ML APIs serve predictions and power real-time applications.
Common SPOFs:
- Single Inference Server Instance: Failure stops all predictions
- Centralized Model Registry: API fails if the registry is down
- Single Load Balancer or Gateway: Outage cuts off all incoming requests
- Single Authentication Provider: If auth is unavailable, API becomes inaccessible
- Model Hot Reloading Without Backup: If the new model fails, service is down
Mitigation Strategies:
- Deploy multiple inference instances behind load balancers
- Use replicated model registries or cache models locally
- Configure multiple load balancer instances or use cloud-managed gateways
- Implement auth fallback mechanisms
- Keep previous model versions for rollback
Single Points of Failure in Training Workflows
Training workflows can be long-running and resource-intensive.
Common SPOFs:
- Single GPU/TPU Node: Hardware failure stalls training
- Single Training Job Manager: Orchestrator crash stops the process
- Centralized Parameter Server: In distributed training, loss of parameter server halts progress
- Non-Checkpointed Training: Loss of progress in case of interruption
- Single Data Preprocessing Node: Bottlenecks data feeding
Mitigation Strategies:
- Use distributed training with worker redundancy
- Deploy multiple orchestrator instances
- Replicate parameter servers or use decentralized synchronization
- Enable frequent checkpointing of models
- Parallelize preprocessing
Understanding RPO & RTO in Machine Learning Workloads
In Disaster Recovery (DR) planning, two critical metrics define recovery goals: Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
For Machine Learning (ML) workloads, these metrics help determine how much data loss and downtime is acceptable, and they directly influence infrastructure, backup, and failover strategies.
Recovery Point Objective (RPO)
The maximum acceptable amount of data loss measured in time. It defines the point in time to which data must be restored after an outage.
Implication for ML:
- Determines how often datasets, feature stores, and model artifacts should be backed up
- A low RPO (e.g., seconds/minutes) means frequent replication or streaming updates
- A high RPO (e.g., hours/days) may allow batch backups but risks losing more recent training data or model updates
Example in ML:
If RPO = 15 minutes, and a training pipeline fails at 2:30 PM, you must be able to restore the system to its state at or after 2:15 PM.
Recovery Time Objective (RTO)
The maximum acceptable amount of downtime after a failure before operations must be restored.
Implication for ML:
- Defines how quickly inference services or pipelines need to be back online
- Low RTO (seconds/minutes) requires hot standbys, active-active clusters, and automated failover
- High RTO (hours/days) allows manual recovery but impacts service-level agreements (SLAs)
Example in ML:
If RTO = 30 minutes, your inference API must be restored and fully operational within 30 minutes of an outage.
RPO & RTO in Different ML Workloads
| ML Workload Type | Typical RPO Needs | Typical RTO Needs |
|---|---|---|
| Real-time Inference APIs | Seconds to minutes | Seconds to minutes |
| Batch Model Training | Hours | Hours to days |
| Feature Store Updates | Minutes to hours | Minutes to hours |
| Data Labeling Pipelines | Hours to days | Hours |
| Model Deployment & Rollback | Minutes | Minutes |
Balancing Cost and Performance
Lowering RPO and RTO increases infrastructure complexity and cost. For ML systems:
- Low RPO/RTO: Suitable for mission-critical inference (e.g., fraud detection, autonomous driving)
- Moderate RPO/RTO: Suitable for non-critical batch workloads (e.g., weekly model retraining)
- High RPO/RTO: Suitable for research or experimental pipelines
¤¦Ā Pro tips
- Classify ML Workloads: Assign RPO/RTO targets based on criticality
- Automate Backups & Replication: For datasets, features, and model artifacts
- Use Multi-Region Deployments: Reduce the risk of total service loss
- Leverage Checkpointing: In long-running training jobs to meet RPO goals
- Regularly Test DR Plans: Validate that recovery meets defined RPO/RTO targets
Strategies for Data & Model Redundancy in ML Systems
Data Redundancy Strategies
Data redundancy protects against loss or unavailability of critical datasets, feature stores, and training inputs.
Multi-Region Storage
Storing copies of datasets and artifacts across multiple geographical regions.
Benefits:
- Protects against regional outages
- Reduces latency for globally distributed users
- Complies with regional data governance laws
Best Practices:
- Use cloud-managed multi-region storage (AWS S3 Cross-Region Replication, GCP Multi-Region Buckets, Azure GRS)
- Regularly verify replication integrity
- Maintain consistent access policies across regions
Replication
Maintaining one or more synchronized copies of data across different locations or systems.
Types:
- Synchronous Replication: Real-time data copying; ensures zero data loss but higher latency
- Asynchronous Replication: Near-real-time copying; minimal impact on performance but risk of small data loss
Model Redundancy Strategies
Model redundancy ensures prediction services remain available even when a particular model instance or environment fails.
Multi-Endpoint Deployments
Hosting the same model across multiple endpoints, servers, or regions.
Benefits:
- Improves uptime through failover
- Enables load balancing for performance scaling
- Allows canary or blue-green deployments for safe updates
Model Versioning & Rollback
Keeping multiple versions of models available for quick rollback.
Best Practices:
- Store models in a versioned model registry
- Automate rollback in case of degraded performance
- Maintain compatibility between model versions
Edge & Cloud Hybrid Redundancy
Deploying models both at the edge and in the cloud for dual availability.
Benefits:
- Reduces latency for local predictions
- Provides fallback to cloud inference during edge device failures
Key Considerations
- Cost vs. Redundancy: More redundancy increases costsŌĆöbalance based on SLA needs
- Consistency Models: For data replication, choose between strong consistency and eventual consistency
- Security: Encrypt data and models at rest and in transit
- Testing: Regularly simulate failover and recovery
Infrastructure-Level High Availability for ML Systems
Kubernetes for High Availability
Kubernetes provides the foundation for container orchestration, scalability, and fault tolerance.
Multi-Zone/Multi-Region Clusters
- Deploy worker nodes across multiple Availability Zones (AZs) or regions
- Prevents downtime if one AZ fails
- Use cloud-managed Kubernetes services (EKS, GKE, AKS) for automatic control plane HA
ReplicaSets & Horizontal Pod Autoscaling (HPA)
- ReplicaSets: Maintain multiple identical pods for redundancy
- HPA: Automatically adjusts the number of pods based on CPU, GPU, or custom metrics
StatefulSets for ML Components
- Ideal for stateful ML workloads like feature stores or model metadata services
- Use persistent volumes with multi-AZ replication
Pod Disruption Budgets (PDBs)
- Prevent excessive pod evictions during maintenance or upgrades
- Ensure minimum service availability
Cloud Load Balancers for HA
Cloud load balancers distribute traffic across multiple endpoints, improving reliability and performance.
Types of Load Balancers
- L4 Load Balancers (Network LB): Low latency, protocol-agnostic
- L7 Load Balancers (Application LB): Content-based routing for ML APIs
Global Load Balancing
- Distributes traffic across regions
- Supports geo-routing for low-latency inference
- Examples: AWS Global Accelerator, Google Cloud Load Balancing, Azure Front Door
Health Checks & Failover
- Regularly probe ML API endpoints
- Automatically remove unhealthy endpoints from rotation
- Enable automated failover to backup clusters
Managed Services for HA
Managed services offload the operational complexity of scaling, replication, and failover.
Managed Databases & Feature Stores
- Examples: AWS RDS, Google BigQuery, Feast on GCP
- Use multi-AZ or multi-region deployment options
- Automatic backups and replication
Managed Model Hosting
- Examples: AWS SageMaker Endpoints, Vertex AI Endpoints, Azure ML Endpoints
- Provide built-in scaling and endpoint health monitoring
Managed Message Queues & Streaming
- Examples: AWS SQS/SNS, Google Pub/Sub, Azure Event Hubs
- Use for decoupling ML pipeline stages
- Ensure multi-AZ replication for event durability
¤¦Ā Pro Tips
- Spread Workloads: Distribute workloads across multiple zones and nodes
- Enable Auto-Healing: Use Kubernetes liveness/readiness probes
- Test Failover: Regularly simulate node/zone failures
- Use Managed Services: Reduce operational overhead
- Monitor & Alert: Track system health with Prometheus, Grafana, or cloud-native monitoring
Automated Failover & Disaster Recovery Runbooks for ML Inference Services
Automated Failover for ML Inference Services
Failover Design Principles
- Minimize Downtime: Immediate redirection of traffic to healthy endpoints
- Reduce Manual Intervention: Automate detection and switchovers
- Maintain Consistency: Ensure models and dependencies match across failover endpoints
Architecture Components
- Health Checks: Periodically test inference API endpoints
- Load Balancers / API Gateways: Route traffic to healthy instances
- Multi-Region Deployments: Run inference services in multiple regions or availability zones
- Traffic Routing Policies: Active-active or active-passive configurations
Failover Automation Tools
- Cloud-native services: AWS Route 53 Failover, GCP Cloud Load Balancing, Azure Traffic Manager
- Kubernetes-native: Service mesh (Istio, Linkerd), K8s readiness/liveness probes, Argo Rollouts
- CI/CD Integration: Automate redeployment to secondary clusters
Disaster Recovery (DR) Runbooks for Inference Services
A DR runbook is a documented and automated sequence of actions to restore service after an outage.
Key Steps in an ML Inference DR Runbook
- Detect Outage: Monitoring tools trigger alerts on service downtime
- Initiate Failover: Route traffic to backup inference endpoints
- Verify Backup Availability: Ensure models are loaded and functional
- Restore Primary Service: Fix underlying issues in the primary environment
- Failback Traffic: Gradually redirect traffic to the restored primary
DR Runbook Example
steps:
- name: Detect outage
action: PagerDuty alert from Prometheus
- name: Switch traffic
action: Update DNS via Route 53 failover policy
- name: Validate backup endpoint
action: Run smoke tests against backup endpoint
- name: Restore primary
action: Redeploy inference service in primary cluster
- name: Failback
action: Route traffic back to primary endpointBackup & Restore Strategies for ML Assets
Datasets
- Backup: Store raw and processed datasets in geo-redundant object storage (S3, GCS, Azure Blob)
- Restore: Maintain dataset versioning for reproducibility (DVC, LakeFS)
Feature Stores
- Backup: Use built-in replication for managed feature stores
- Restore: Restore from point-in-time snapshots
Models
- Backup: Store models in versioned registries (MLflow, SageMaker Model Registry, Vertex AI Model Registry)
- Restore: Deploy the desired version to inference endpoints during recovery
Metadata
- Backup: Regularly export metadata from orchestration tools (Airflow, Kubeflow)
- Restore: Re-import metadata for pipeline continuity
¤¦Ā Best Practices
- Automate Everything: Use IaC and scripts for backups, failover, and restores
- Test Regularly: Perform DR drills to validate runbook effectiveness
- Align with RPO/RTO: Ensure backup frequency and failover time meet SLA targets
- Monitor Recovery: Track metrics during failover and restore to improve processes
- Secure Backups: Encrypt in transit and at rest, with strict access control
¤öź Challenges
- Designing HA for training pipelines without significantly increasing costs
- Keeping data & model backups in sync with real-time changes
- Balancing latency vs. resilience in multi-region deployments
- Automating failover without false positives causing service disruption
- Testing DR plans regularly in production-like environments
- Maintaining compliance with data residency laws in multi-region storage
- Ensuring ML metadata (experiments, metrics, lineage) is backed up and recoverable